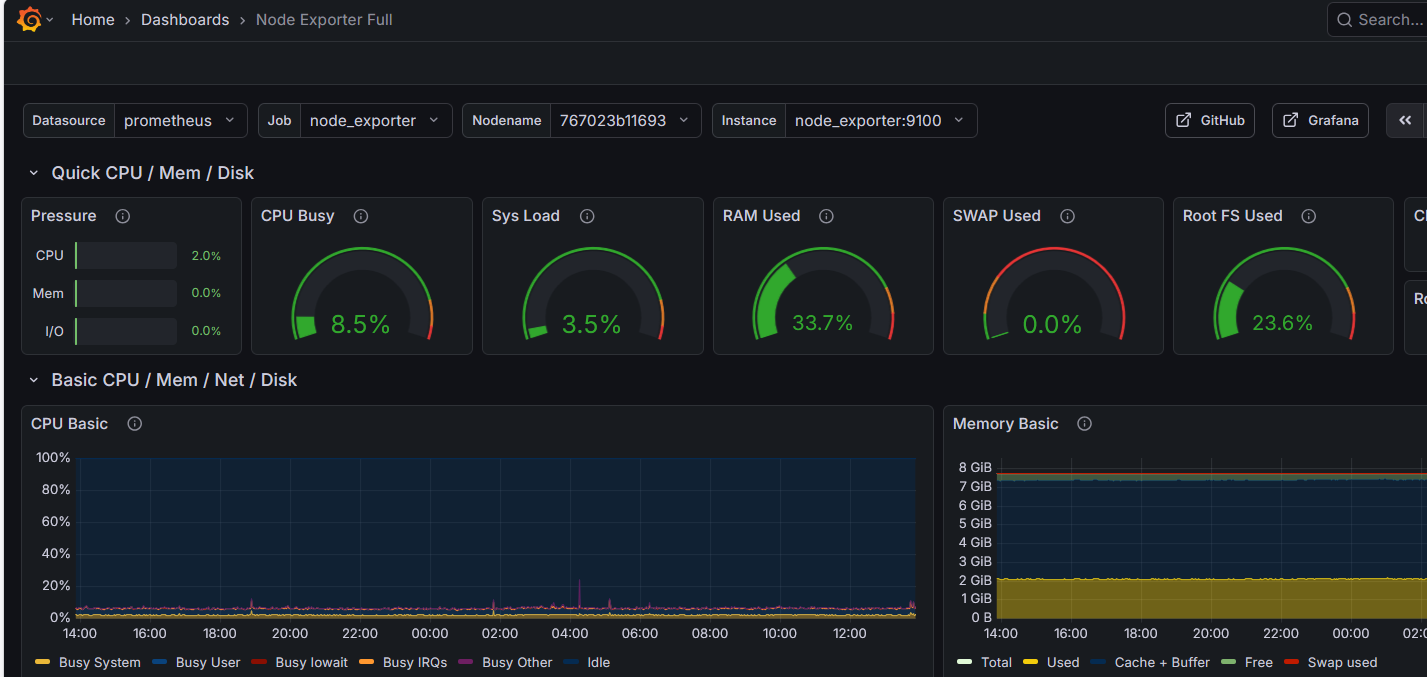
Como se configuran las Alertas y Notificaciones en Dynatrace

:: Artículo actualizado en abril de 2025 :: Configurar alertas en Dynatrace es uno de los primeros retos con los que se encuentra cualquier persona que empieza a trabajar con la plataforma. No porque sea complicado técnicamente, sino porque Dynatrace ofrece varios mecanismos distintos para conseguir lo mismo, y no siempre queda claro cuál usar … Leer más