
Llevo más de 15 años en el mundo de la monitorización. He trabajado con plataformas enterprise de diferentes fabricantes, he participado en migraciones complejas, he visto evolucionar herramientas a lo largo del tiempo, y he estado en proyectos tanto con soluciones comerciales como open source. He visto empresas migrar de una plataforma a otra, he presenciado convivencias imposibles entre herramientas, y he trabajado con equipos técnicos exhaustos intentando mantener varios ecosistemas funcionando a la vez.
El otro día, leyendo un artículo sobre Clean Code en la newsletter de xurxodev.com, algo hizo clic en mi cabeza. El autor explicaba que ser un buen desarrollador no consiste en dominar JavaScript, Python o Java, sino en aplicar principios y estrategias que funcionan independientemente del lenguaje que uses. La herramienta es secundaria; lo importante es la metodología, el pensamiento estructurado, la capacidad de escribir código limpio y mantenible que trascienda la sintaxis particular de turno.
Y ahí estaba yo, con 15 años de experiencia en monitoring, pensando: «Esto es exactamente lo que le falta a la industria de la observabilidad».
Porque he visto el patrón repetirse una y otra vez: una organización decide que necesita «mejor monitorización». Se lanzan a evaluar herramientas. Contratan la solución enterprise del momento, o montan un stack open source complejo. Y entonces empieza la pregunta que lo infecta todo: «¿Cómo se hace esto en [nombre de la herramienta]?»
Cuando la pregunta debería ser: «¿Qué necesitamos monitorizar y por qué?»
Esta inversión de prioridades —herramienta antes que estrategia— es la raíz de los Frankensteins que veo en producción: múltiples herramientas conviviendo porque nadie terminó la migración, equipos funcionales cada uno pidiendo «su monitor», prácticas on-premise mezcladas con cloud sin coherencia alguna, y equipos técnicos quemados manteniendo todo ese ecosistema mientras el negocio presiona por cumplir los SLAs.
Si en programación hablamos de Clean Code, es hora de que en nuestro campo hablemos de Clean Monitoring: una estrategia de observabilidad que sea agnóstica de la herramienta, que sobreviva a las migraciones, que escale cuando la infraestructura evolucione, y que —esto es crucial— funcione igual de bien si mañana pasas de on-premise a cloud, de monolitos a microservicios, o de VMs a serverless.
Porque las herramientas van y vienen. Pero tu estrategia debería quedarse.
El Frankenstein de la monitorización: un problema más común de lo que parece

Si trabajas en este sector, probablemente reconocerás este escenario. O quizá lo estés viviendo ahora mismo.
Una organización tiene una plataforma de monitorización que lleva años funcionando. No es perfecta, pero funciona. Monitoriza servidores, aplicaciones, bases de datos. Los equipos la conocen, tienen sus dashboards, sus alertas configuradas. Todo relativamente estable.
Entonces llega el momento del cambio. Puede ser por diferentes razones: la herramienta actual se ha quedado obsoleta, los costes de licenciamiento se han disparado, el fabricante ha cambiado su modelo de negocio, o simplemente alguien en dirección ha asistido a un evento donde le han vendido «la solución definitiva» para observabilidad.
Se toma la decisión: vamos a migrar a una nueva plataforma.
Y aquí es donde empieza el verdadero problema.
La migración que nunca termina
La nueva herramienta se despliega. Se empieza a configurar. Pero la antigua no se puede apagar todavía porque hay monitores críticos que aún no se han migrado. «Solo será temporal», dicen. «En tres meses estamos fuera de la vieja plataforma».
Tres meses se convierten en seis. Seis en doce. Y de repente llevas dos años con ambas plataformas funcionando en paralelo. Cada una con su infraestructura, sus agentes, su consumo de recursos, sus licencias. El doble de todo.
Pero espera, que la cosa se complica más.
Cuando el cloud entra en escena
Mientras tanto, la organización ha empezado su transformación cloud. Hay cargas de trabajo migrando a AWS, a Azure, o a ambos. Aparecen contenedores, Kubernetes, funciones serverless. Y estos nuevos componentes necesitan monitorización también.
Ahora no son dos herramientas. Son dos herramientas legacy para on-premise, más las capacidades nativas de AWS CloudWatch, más Azure Monitor, más quizá alguna herramienta específica para Kubernetes porque «es que los contenedores son diferentes».
El Frankenstein está completo: múltiples plataformas, múltiples paradigmas tecnológicos, múltiples fuentes de verdad.
El día a día del equipo técnico
Y en medio de todo esto están los equipos técnicos. Los especialistas de monitorización, los sysadmins, los SREs. Su día a día se ha convertido en un ejercicio constante de malabarismo:
- El equipo de bases de datos pide un monitor nuevo. «¿En qué herramienta lo configuramos? Ah, pues en las dos, porque todavía consultan la antigua…»
- Llega una incidencia. «¿Dónde miramos? Porque esta aplicación tiene parte en on-premise monitorizándose en la plataforma vieja, y parte en cloud con CloudWatch…»
- Hay que hacer un informe de disponibilidad. Datos de tres sitios diferentes, con métricas que no son exactamente comparables entre sí.
- El equipo de Windows quiere que se monitorice igual que antes. El de Unix tiene otras necesidades. El de cloud pide agilidad y automatización. Todos tienen razón, pero implementarlo en este contexto es agotador.
La presión del negocio
Y mientras tanto, el negocio no para. Los SLAs siguen vigentes. Las incidencias siguen llegando. Los usuarios finales no saben —ni les importa— que internamente tenemos cuatro herramientas de monitorización intentando hablar entre sí.
Cuando algo falla, esperan que lo detectemos rápido y lo resolvamos más rápido aún. No importa si el problema está en un servidor físico de hace diez años, en una VM en VMware, en un contenedor en EKS, o en una Lambda. Tiene que funcionar.
La pregunta equivocada
Y en medio de este caos, ¿cuál es la conversación que más se repite en las reuniones?
«¿Cómo configuramos esto en [la nueva herramienta]?» «¿Dónde está el manual de [plataforma X] para hacer [cosa Y]?» «¿Alguien ha hecho un curso de [herramienta Z]?»
Preguntas centradas en la herramienta. En el «cómo». Nunca en el «qué» ni en el «por qué».
Porque lo cierto es que nadie se sentó al principio a definir una estrategia clara de qué necesitábamos monitorizar, con qué nivel de detalle, con qué criticidad, con qué objetivos de SLO. Se compró primero la herramienta, y luego se empezó a ver qué se podía hacer con ella.
Y así es como acabas con un Frankenstein.
La raíz del problema: estrategia acoplada a la herramienta
¿Por qué acabamos una y otra vez en estas situaciones? ¿Es mala suerte? ¿Falta de planificación? ¿Malas decisiones técnicas?
En realidad, hay una causa más profunda, y tiene que ver con cómo abordamos el problema desde el principio.
El enfoque tradicional (y equivocado)
El proceso habitual suele ser algo así:
- Identificamos que tenemos un problema con la monitorización actual
- Evaluamos herramientas del mercado
- Elegimos una (normalmente basándonos en demos, presentaciones comerciales, o lo que está de moda)
- La compramos/contratamos
- Empezamos a configurar y ver qué podemos hacer con ella
- Intentamos replicar lo que teníamos antes, pero en la nueva plataforma
- Los equipos piden sus monitores específicos y vamos respondiendo sobre la marcha
¿Ves el problema? La estrategia se define DESPUÉS de elegir la herramienta, no antes.
Es como si un arquitecto eligiera primero los materiales de construcción y luego se pusiera a pensar qué edificio va a diseñar. «Bueno, tenemos mucho acero y cristal, así que supongo que haremos algo moderno…»
El acoplamiento invisible
Cuando haces esto, estás acoplando tu estrategia de monitorización a una herramienta concreta. Y ese acoplamiento es invisible al principio, pero mortal a largo plazo.
Tu estrategia pasa a ser: «Monitorizamos como lo hace [nombre de la herramienta]» Tus procesos se diseñan alrededor de las capacidades (y limitaciones) de esa plataforma específica. Tu equipo aprende «cómo se hace en [herramienta X]», no «cómo se diseña una buena estrategia de observabilidad». Tu documentación está llena de capturas de pantalla y rutas de menús específicas.
Y entonces, cuando llega el momento de cambiar —por evolución tecnológica, por costes, por adquisiciones corporativas, por lo que sea— te das cuenta de que no puedes.
O más bien, puedes, pero es dolorosísimo. Porque no estás migrando de una herramienta a otra. Estás intentando reconstruir toda tu estrategia desde cero, porque estaba tan acoplada a la herramienta anterior que no existe fuera de ella.
El problema se multiplica con la evolución tecnológica
Y aquí está la verdadera «madre del cordero», como decíamos antes.
Porque el problema no es solo cambiar de herramienta. El problema es que tu infraestructura también evoluciona, y tu estrategia debe sobrevivir a esos cambios.
Piénsalo:
- Empezaste monitorizando servidores físicos en tu datacenter. Tu estrategia se diseñó para ese mundo: agentes instalados, métricas de hardware, checks de procesos…
- Luego vinieron las máquinas virtuales. Bueno, no es tan diferente, sigues teniendo «servidores», así que más o menos adaptas lo mismo.
- Después llega el cloud. IaaS, vale, todavía son máquinas virtuales, aunque ahora son efímeras y escalan dinámicamente. Empiezas a notar que tu estrategia cruje un poco, pero todavía aguanta.
- Contenedores. Kubernetes. Ahora ya no tienes «servidores» en el sentido tradicional. Tienes pods que nacen y mueren constantemente. ¿Monitorizas el contenedor? ¿El pod? ¿El node? ¿El cluster?
- Serverless. Funciones que existen durante milisegundos. ¿Cómo instalas un agente ahí? ¿Tiene sentido siquiera pensar en «agentes»?
Si tu estrategia estaba acoplada a «así es como la herramienta X monitoriza servidores tradicionales», ahora estás perdido.
El síntoma: la pregunta equivocada
Y por eso la pregunta que escuchas constantemente es: «¿Cómo hacemos esto en [herramienta Y]?»
Porque nunca se definió el «esto» de forma independiente. El «esto» siempre fue «como lo hacíamos en [herramienta anterior]» o «como nos enseñaron en el curso de [herramienta actual]».
No hay una definición clara de:
- Qué componentes críticos tenemos
- Qué significa que cada componente esté «funcionando correctamente»
- Qué métricas son realmente importantes vs. cuáles son ruido
- Qué SLOs tenemos definidos para cada servicio
- Cómo priorizamos qué monitorizar primero
La consecuencia: dependencia, no estrategia
Y aquí está el quid de la cuestión: si tu forma de monitorizar solo funciona con una herramienta específica, o con un tipo de infraestructura específica, entonces no tienes una estrategia.
Tienes una dependencia.
Una dependencia de un fabricante concreto. Una dependencia de un paradigma tecnológico concreto. Una dependencia que te hace vulnerable cada vez que algo cambia.
Y en tecnología, lo único constante es el cambio.
Clean Monitoring: los principios agnósticos
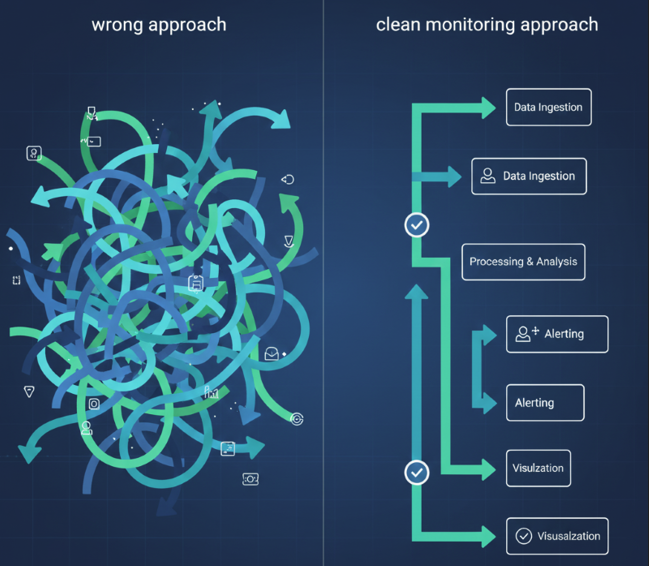
Si el problema es el acoplamiento entre estrategia y herramienta, la solución es diseñar una estrategia que sea agnóstica de la herramienta y del paradigma tecnológico.
Igual que en Clean Code los principios de buen diseño funcionan en cualquier lenguaje de programación, en Clean Monitoring los principios de buena observabilidad deben funcionar independientemente de la herramienta que uses o de cómo esté construida tu infraestructura.
Pero, ¿cómo se hace eso en la práctica? Aquí están los pilares fundamentales:
1. Inventario antes que herramienta
Antes de evaluar herramientas, antes incluso de pensar en qué vas a monitorizar, necesitas saber qué tienes.
Y no me refiero a un listado de servidores o VMs. Me refiero a un inventario conceptual:
- ¿Qué servicios de negocio ofreces?
- ¿Qué componentes técnicos soportan cada servicio?
- ¿Cuáles son las dependencias entre componentes?
- ¿Qué flujos de datos críticos existen?
Este inventario debe ser agnóstico de la implementación. «Servicio de pagos» es el concepto, da igual si hoy está en un monolito Java corriendo en un Tomcat on-premise, o si mañana son 5 microservicios en Kubernetes en AWS.
Sin este inventario claro, estarás monitorizando infraestructura sin entender qué estás protegiendo realmente.
2. Estrategia de tagging coherente y significativa
El tagging es probablemente uno de los aspectos más subestimados y más críticos de una buena estrategia de monitorización.
Y la clave está en que el tagging debe basarse en el negocio, no en la tecnología.
Mal enfoque:
servidor: web-prod-01SO: linuxdatacenter: DC1
Buen enfoque:
servicio: pagoscriticidad: criticaequipo: payments-teamentorno: produccion
¿Por qué? Porque el primer enfoque se rompe cuando cambias de infraestructura. El servidor web-prod-01 desaparece cuando migras a contenedores. Pero el servicio de pagos sigue existiendo, sigue siendo crítico, y sigue siendo responsabilidad del payments-team.
Un tagging bien diseñado:
- Sobrevive a cambios de infraestructura
- Facilita la segmentación por equipos
- Permite priorizar por criticidad
- Funciona en cualquier herramienta que soporte tags/labels
3. Define tus SLIs y SLOs desde el principio
Aquí está el corazón de una estrategia agnóstica: definir qué significa que algo funcione correctamente, independientemente de cómo esté implementado.
Un SLO (Service Level Objective) bien definido es agnóstico:
- «El servicio de pagos debe completar el 99.9% de las transacciones en menos de 2 segundos»
- «La API de búsqueda debe estar disponible el 99.95% del tiempo»
- «El proceso de onboarding de usuarios debe tener una tasa de error inferior al 0.1%»
Estos objetivos son válidos tanto si tu servicio corre en bare metal como si corre en lambdas. Lo que cambia es cómo mides esas métricas, no qué estás midiendo.
Y a partir de estos SLOs derivas tus SLIs (Service Level Indicators): las métricas concretas que te dirán si estás cumpliendo o no el objetivo.
4. Prioriza lo crítico de lo secundario
No todo necesita el mismo nivel de monitorización. Y esta priorización debe ser explícita y estar documentada.
Componentes críticos:
- Monitorización proactiva
- Alertas 24/7
- Múltiples dimensiones (performance, disponibilidad, errores)
- Alertas a múltiples canales
Componentes secundarios:
- Monitorización básica
- Revisión en horario laboral
- Métricas fundamentales
Componentes de desarrollo/test:
- Monitorización mínima o ninguna
Esta matriz de priorización es agnóstica. Da igual si mañana el componente crítico cambia de tecnología; sigue siendo crítico y sigue necesitando ese nivel de monitorización.
5. Modelo de datos consistente
Define cómo estructuras tu información de observabilidad de forma que sea portable:
- Métricas: ¿Qué convenciones de nombres usas? ¿Qué dimensiones incluyes siempre?
- Logs: ¿Qué formato? ¿Qué campos obligatorios? ¿Qué niveles de severidad?
- Traces: ¿Cómo identificas transacciones? ¿Qué metadatos incluyes?
Si defines esto de forma estándar (OpenTelemetry es un buen ejemplo de estándar abierto), tu código de instrumentación es portable. Cambias de backend de observabilidad, pero no cambias cómo instrumentas tu aplicación.
6. Automatización y código como fuente de verdad
La configuración de tu monitorización debe estar en código. Infrastructure as Code, pero también Monitoring as Code.
¿Por qué? Porque:
- Es versionable
- Es auditable
- Es reproducible
- Es testeable
- Es portable
Si tu monitorización está en código (Terraform, Ansible, scripts, lo que sea), cuando cambias de herramienta o escalas tu infraestructura, re-despliegas. No reconstruyes manualmente 500 monitores haciendo click en una interfaz web.
El enfoque correcto: de la estrategia a la herramienta
Con estos principios, el flujo de trabajo cambia completamente:
Antes (acoplado): Elegir herramienta → Ver qué puede hacer → Configurar → Ir respondiendo a peticiones
Ahora (agnóstico):
- Inventario: Qué servicios y componentes tenemos
- Priorización: Qué es crítico, qué es secundario
- SLOs: Qué significa que cada cosa funcione correctamente
- Tagging: Cómo etiquetamos todo de forma coherente
- Modelo de datos: Cómo estructuramos métricas, logs, traces
- Estrategia documentada: Todo lo anterior, por escrito
- Evaluación de herramientas: Ahora sí, qué herramienta implementa mejor nuestra estrategia
- Implementación: Desplegar la estrategia usando la herramienta elegida
- Formación: Enseñar al equipo cómo usar esa herramienta concreta
Fíjate en que la herramienta aparece en el punto 7, no en el punto 1.
Y lo más importante: del punto 1 al 6, todo es reutilizable. Si dentro de tres años cambias de herramienta, repites los pasos 7, 8 y 9. Pero tu estrategia (puntos 1-6) sigue siendo válida.
El rol dual: responsabilidad compartida
Implementar Clean Monitoring no es responsabilidad solo de una persona o un rol. Requiere un enfoque dual donde tanto quien toma las decisiones como quien las ejecuta tienen papeles críticos.
Para quien decide (CTO, Director de IT, Arquitecto):
Tu responsabilidad no es elegir la herramienta. Tu responsabilidad es exigir que exista una estrategia antes de evaluar herramientas.
Antes de aprobar presupuesto para una nueva plataforma de observabilidad, pregunta:
- ¿Tenemos documentado qué servicios son críticos y por qué?
- ¿Están definidos los SLOs de cada servicio?
- ¿Existe una estrategia de tagging coherente?
- ¿Cómo vamos a medir el éxito de esta herramienta más allá de «está instalada»?
Si las respuestas no están claras, detén el proceso. Invertir tres semanas en definir la estrategia te ahorrará tres años de Frankenstein.
Y cuando ya estés en medio del Frankenstein (porque seamos honestos, muchos ya lo estamos), reconoce el coste real: no solo las licencias duplicadas, sino el burnout del equipo, la fricción operativa, el riesgo de no detectar incidencias críticas porque «no sabemos en cuál de las tres herramientas mirar».
Para el técnico (Especialista de monitoring, SRE, Sysadmin):
Tu rol no es solo «implementar lo que te piden». Eres el guardián de la estrategia agnóstica.
Esto significa:
- Educar: Cuando te pidan «configurar este monitor en [herramienta]», pregunta primero: «¿Qué estamos intentando proteger? ¿Qué SLO estamos cubriendo?»
- Diseñar abstracciones: No documentes «cómo se hace en [herramienta X]», documenta «qué necesitamos monitorizar y por qué». Luego, crea documentación específica de herramienta como implementación de esa estrategia.
- Pensar en evolución: Cuando diseñes algo, pregúntate: «Si el año que viene esto migra a Kubernetes, ¿mi estrategia sigue funcionando? ¿O tengo que empezar desde cero?»
- Evangelizar: Sé la voz que recuerda constantemente que la herramienta es temporal, la estrategia es permanente.
No es fácil. Especialmente cuando estás en medio del caos, con alertas sonando, equipos pidiendo cosas, y presión por entregar rápido. Pero es en esos momentos cuando más necesario es mantener la disciplina.
La colaboración es clave
Lo ideal es que ambos roles trabajen juntos desde el principio:
- El decisor aporta visión de negocio, prioridades estratégicas, presupuesto
- El técnico aporta conocimiento de la realidad operativa, viabilidad, implementación
Juntos definen la estrategia agnóstica. Y luego, solo entonces, eligen la herramienta que mejor la implementa.
Conclusión: la estrategia es tuya, las herramientas son temporales
He visto demasiadas migraciones dolorosas. Demasiados equipos quemados. Demasiadas organizaciones atrapadas en Frankensteins de su propia creación.
Y casi siempre la raíz del problema es la misma: se eligió la herramienta antes de definir la estrategia.
Clean Monitoring no es una metodología compleja. No requiere certificaciones ni consultores carísimos. Requiere disciplina y un cambio de mentalidad:
Deja de preguntarte «¿Cómo se hace esto en [herramienta X]?»
Empieza a preguntarte «¿Qué necesito monitorizar, por qué, y con qué nivel de criticidad?»
Define tu inventario. Diseña tu tagging. Establece tus SLOs. Prioriza. Documenta. Todo esto antes de tocar una sola herramienta.
Porque las herramientas van a cambiar. Dynatrace, Datadog, New Relic, Prometheus, o la que venga mañana. Todas son temporales.
Pero tu estrategia, si la diseñas bien, es tuya para siempre.
Y cuando tu infraestructura evolucione —de on-premise a cloud, de VMs a contenedores, de monolitos a microservicios— tu estrategia evolucionará contigo. No tendrás que reconstruirla desde cero.
Porque habrás aplicado Clean Monitoring.
Y al igual que el Clean Code hace que tu software sea mantenible, escalable y duradero, el Clean Monitoring hará que tu observabilidad sea resiliente, adaptable y sostenible.
Tu yo del futuro (y tu equipo) te lo agradecerán.
