Montar un stack completo de monitoreo open source usando Docker Compose para aprender los conceptos fundamentales de observabilidad: recolección de métricas, visualización y alertas.
Tiempo estimado: 30-45 minutos
Dificultad: Intermedia
Infraestructura: Ubuntu Server en VirtualBox
Temas tratados:
- ✅ Configurar Prometheus para recolectar métricas del sistema
- ✅ Crear dashboards profesionales en Grafana
- ✅ Configurar alertas basadas en métricas (CPU, RAM, disco)
- ✅ Entender la arquitectura del stack de monitoreo moderno
- ✅ Generar y visualizar alertas en tiempo real
Arquitectura del Stack
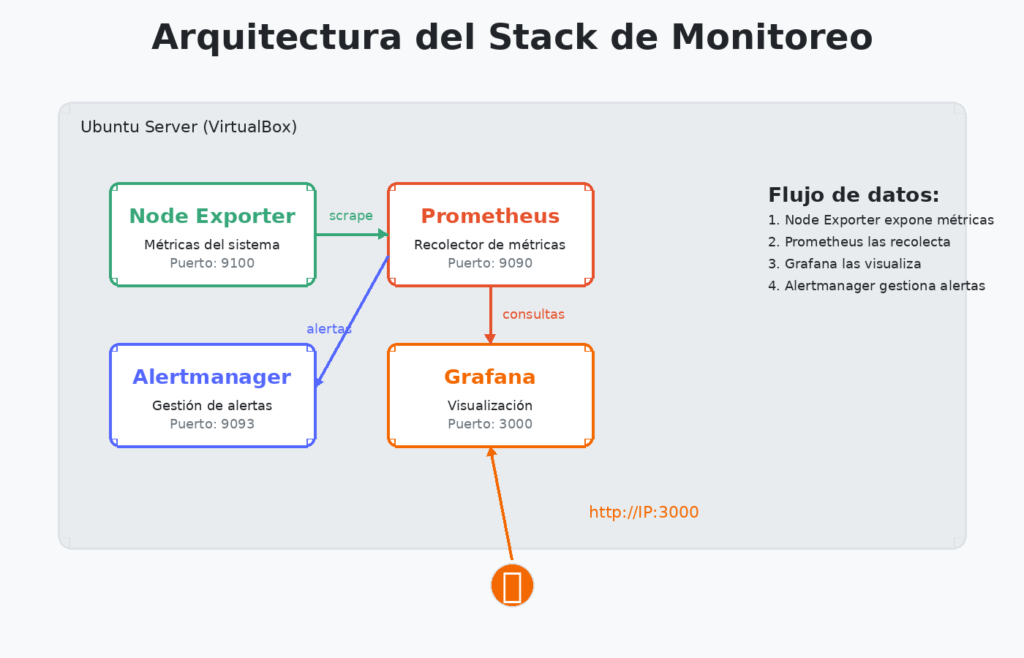
Componentes:
- Prometheus: Motor de métricas que recolecta y almacena datos
- Grafana: Interfaz de visualización para crear dashboards
- Node Exporter: Exporta métricas del sistema (CPU, RAM, disco, red)
- Alertmanager: Gestiona y enruta las alertas
📋 Requisitos Previos
Hardware Mínimo
- RAM: 2GB (4GB recomendado)
- CPU: 2 cores
- Disco: 10GB libres
Software Necesario
- Ubuntu Server 22.04 o 24.04 en VirtualBox
- Docker y Docker Compose instalados
- Acceso SSH a la VM
🌐 Configuración de Red en VirtualBox
Para acceder a Grafana desde tu navegador, configura la red de tu VM:
Opción 1 – Adaptador Puente (Recomendado si funciona en tu red):
- VirtualBox → Configuración de tu VM → Red → Adaptador 1
- «Conectado a:» → Selecciona Adaptador puente
- Inicia la VM
- Dentro de la VM, obtén la IP:
hostname -I - Desde tu navegador:
http://IP_DE_LA_VM:3000
Opción 2 – NAT con Port Forwarding (Siempre funciona):
- VirtualBox → Configuración de tu VM → Red → Adaptador 1 → NAT
- Clic en Avanzadas → Reenvío de puertos
- Añade esta regla (botón +):
- Nombre: Grafana
- Protocolo: TCP
- Puerto anfitrión: 3000
- Puerto invitado: 3000
- Desde tu navegador:
http://localhost:3000
💡 Nota: Solo necesitas el puerto 3000 (Grafana). Los demás servicios (Prometheus, Alertmanager) se acceden desde Grafana.
Opcional: Si quieres acceder directamente a Prometheus (9090) o Alertmanager (9093), añade esos puertos también.
Verificar instalación de Docker:
# Verificar Docker
docker --version
# Verificar Docker Compose
docker-compose --version
Si no tienes Docker instalado:
# Instalar Docker
curl -fsSL https://get.docker.com -o get-docker.sh
sudo sh get-docker.sh
sudo usermod -aG docker $USER
# Instalar Docker Compose (si no está incluido)
sudo apt update
sudo apt install docker-compose -y
# Verificar instalación
docker --version
docker-compose --version
# Reiniciar sesión para aplicar permisos de grupo
exit
🚀 Paso a Paso
Paso 1: Preparar el Entorno
Crear estructura de directorios:
# Crear directorio del proyecto
mkdir -p ~/prometheus-stack
cd ~/prometheus-stack
# Crear subdirectorios para configuraciones
mkdir -p prometheus grafana alertmanager
Paso 2: Configurar Prometheus
Crear archivo de configuración de Prometheus:
nano prometheus/prometheus.yml
Copiar este contenido:
# Configuración global de Prometheus
global:
scrape_interval: 15s # Frecuencia de recolección de métricas
evaluation_interval: 15s # Frecuencia de evaluación de reglas
# Configuración de Alertmanager
alerting:
alertmanagers:
- static_configs:
- targets:
- alertmanager:9093
# Archivos de reglas de alertas
rule_files:
- /etc/prometheus/alert.rules.yml
# Configuración de scrape (qué métricas recolectar)
scrape_configs:
# Métricas del propio Prometheus
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']
# Métricas del sistema (Node Exporter)
- job_name: 'node'
static_configs:
- targets: ['node-exporter:9100']
Paso 3: Crear Reglas de Alertas
Crear archivo de reglas:
nano prometheus/alert.rules.yml
Copiar este contenido:
groups:
- name: system_alerts
interval: 10s
rules:
# Alerta: CPU alta
- alert: HighCPUUsage
expr: 100 - (avg by(instance) (rate(node_cpu_seconds_total{mode="idle"}[2m])) * 100) > 70
for: 2m
labels:
severity: warning
annotations:
summary: "CPU usage is above 70%"
description: "CPU usage on {{ $labels.instance }} is {{ $value }}%"
# Alerta: Memoria alta
- alert: HighMemoryUsage
expr: (node_memory_MemTotal_bytes - node_memory_MemAvailable_bytes) / node_memory_MemTotal_bytes * 100 > 80
for: 2m
labels:
severity: warning
annotations:
summary: "Memory usage is above 80%"
description: "Memory usage on {{ $labels.instance }} is {{ $value }}%"
# Alerta: Disco alto
- alert: HighDiskUsage
expr: (node_filesystem_size_bytes{fstype!="tmpfs"} - node_filesystem_free_bytes{fstype!="tmpfs"}) / node_filesystem_size_bytes{fstype!="tmpfs"} * 100 > 85
for: 5m
labels:
severity: critical
annotations:
summary: "Disk usage is above 85%"
description: "Disk usage on {{ $labels.instance }} mountpoint {{ $labels.mountpoint }} is {{ $value }}%"
# Alerta: Servicio caído
- alert: ServiceDown
expr: up == 0
for: 1m
labels:
severity: critical
annotations:
summary: "Service is down"
description: "Service {{ $labels.job }} on {{ $labels.instance }} is down"
Paso 4: Configurar Alertmanager
Crear configuración de Alertmanager:
nano alertmanager/alertmanager.yml
Copiar este contenido:
# Configuración global
global:
resolve_timeout: 5m
# Rutas de alertas
route:
group_by: ['alertname', 'cluster', 'service']
group_wait: 10s
group_interval: 10s
repeat_interval: 12h
receiver: 'default'
# Receptores (dónde enviar las alertas)
receivers:
- name: 'default'
# Por ahora solo log, puedes añadir webhook, email, Slack, etc.
# Inhibición de alertas (evitar spam)
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'cluster', 'service']
Paso 5: Crear Docker Compose
Crear el archivo principal:
nano docker-compose.yml
Copiar este contenido:
version: '3.8'
services:
# Prometheus - Motor de métricas
prometheus:
image: prom/prometheus:latest
container_name: prometheus
restart: unless-stopped
ports:
- "9090:9090"
volumes:
- ./prometheus/prometheus.yml:/etc/prometheus/prometheus.yml
- ./prometheus/alert.rules.yml:/etc/prometheus/alert.rules.yml
- prometheus-data:/prometheus
command:
- '--config.file=/etc/prometheus/prometheus.yml'
- '--storage.tsdb.path=/prometheus'
- '--web.console.libraries=/etc/prometheus/console_libraries'
- '--web.console.templates=/etc/prometheus/consoles'
- '--web.enable-lifecycle'
networks:
- monitoring
# Node Exporter - Métricas del sistema
node-exporter:
image: prom/node-exporter:latest
container_name: node-exporter
restart: unless-stopped
ports:
- "9100:9100"
command:
- '--path.rootfs=/host'
volumes:
- /:/host:ro,rslave
networks:
- monitoring
# Grafana - Visualización
grafana:
image: grafana/grafana:latest
container_name: grafana
restart: unless-stopped
ports:
- "3000:3000"
environment:
- GF_SECURITY_ADMIN_USER=admin
- GF_SECURITY_ADMIN_PASSWORD=admin
- GF_USERS_ALLOW_SIGN_UP=false
volumes:
- grafana-data:/var/lib/grafana
networks:
- monitoring
depends_on:
- prometheus
# Alertmanager - Gestión de alertas
alertmanager:
image: prom/alertmanager:latest
container_name: alertmanager
restart: unless-stopped
ports:
- "9093:9093"
volumes:
- ./alertmanager/alertmanager.yml:/etc/alertmanager/alertmanager.yml
- alertmanager-data:/alertmanager
command:
- '--config.file=/etc/alertmanager/alertmanager.yml'
- '--storage.path=/alertmanager'
networks:
- monitoring
networks:
monitoring:
driver: bridge
volumes:
prometheus-data:
grafana-data:
alertmanager-data:
Paso 6: Levantar el Stack
# Verificar que los archivos están correctos
ls -la prometheus/
ls -la alertmanager/
cat docker-compose.yml
# Levantar los contenedores
docker-compose up -d
# Verificar que todo está corriendo
docker-compose ps
# Ver logs en tiempo real (Ctrl+C para salir)
docker-compose logs -f
Salida esperada:
NAME IMAGE STATUS
prometheus prom/prometheus:latest Up
node-exporter prom/node-exporter:latest Up
grafana grafana/grafana:latest Up
alertmanager prom/alertmanager:latest Up
Paso 7: Verificar Acceso Web
Acceder a Grafana desde tu navegador:
- Si usas Adaptador Puente:
http://IP_DE_LA_VM:3000 - (Para saber tu IP, ejecuta en la VM:
hostname -I) - Si usas NAT:
http://localhost:3000
Credenciales por defecto:
- Usuario:
admin - Password:
admin
💡 Todo el lab se hace desde Grafana. Los demás servicios (Prometheus, Alertmanager) se acceden internamente.
Para curiosos: Si quieres ver las UIs de otros servicios:
- Prometheus: puerto 9090
- Alertmanager: puerto 9093
- Node Exporter (métricas raw): puerto 9100
Paso 8: Configurar Grafana
8.1 Primer login
- URL:
http://TU_IP:3000 - Usuario:
admin - Password:
admin - Te pedirá cambiar la contraseña (puedes usar
admin123para el lab)
8.2 Añadir Prometheus como Data Source
- Click en ☰ (menú) → Connections → Data sources
- Click Add data source
- Seleccionar Prometheus
- Configurar:
- Name: Prometheus
- URL:
http://prometheus:9090 - Dejar el resto por defecto
- Click Save & test → Debe salir «Data source is working»
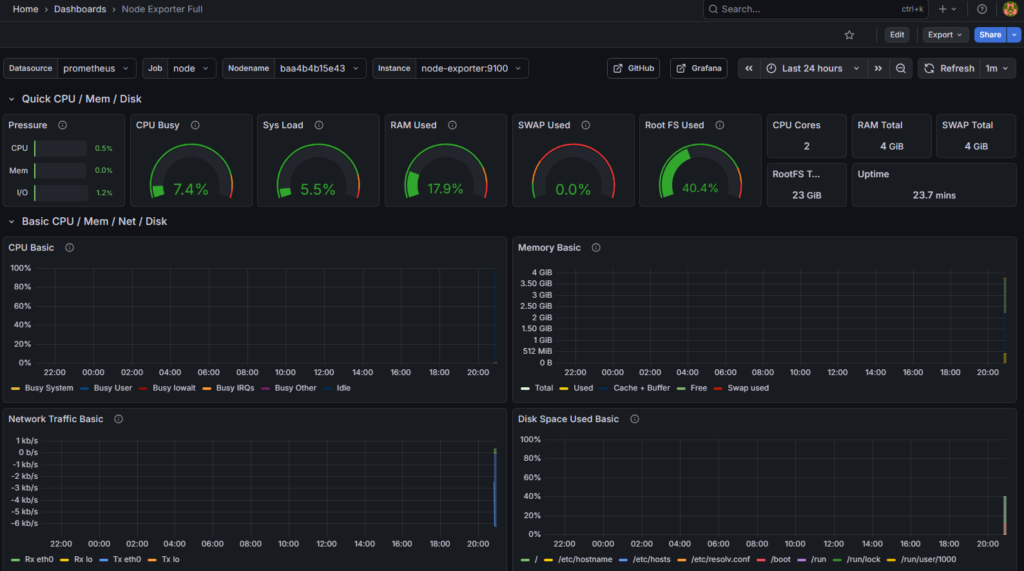
8.3 Importar Dashboard pre-hecho
- Click en ☰ → Dashboards → Import
- En Import via grafana.com: escribir
1860 - Click Load
- Configurar:
- Name: Node Exporter Full
- Prometheus: Seleccionar «Prometheus» (el que acabas de crear)
- Click Import

¡BOOM! 💥 Ya tienes un dashboard profesional con métricas en tiempo real
Paso 9: Probar las Alertas
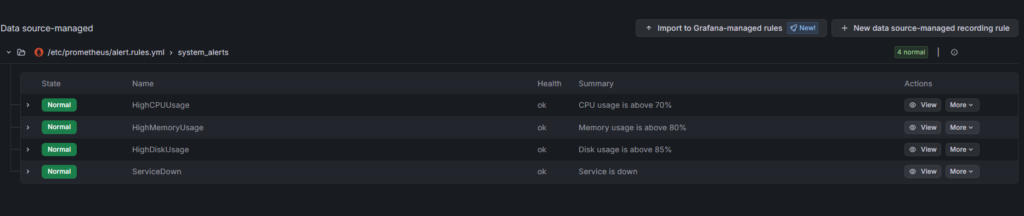
9.1 Verificar que las reglas están cargadas
Desde Grafana (recomendado):
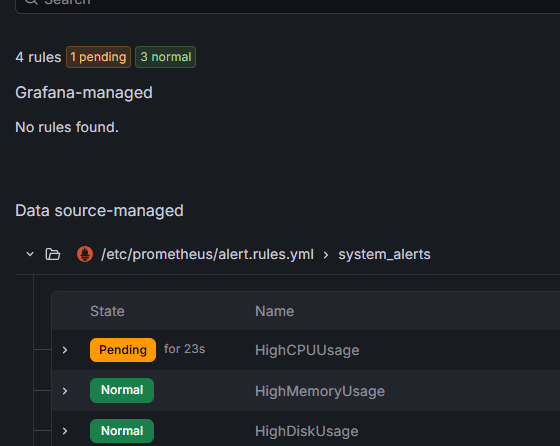
- Ir a Grafana → 🔔 Alerting → Alert rules
- Deberías ver las 4 reglas configuradas
Alternativamente desde Prometheus:
- Si configuraste el puerto 9090, ir a
http://TU_IP:9090(olocalhost:9090) - Click en Status → Rules
9.2 Generar carga de CPU para disparar alerta
# Instalar stress (si no lo tienes)
sudo apt update && sudo apt install -y stress
# Generar carga de CPU al 100% durante 3 minutos
stress --cpu 4 --timeout 180s
# Alternativa sin instalar nada:
dd if=/dev/zero of=/dev/null &
dd if=/dev/zero of=/dev/null &
dd if=/dev/zero of=/dev/null &
# Esperar 2-3 minutos y luego matar los procesos:
# killall dd
9.3 Ver la alerta activarse
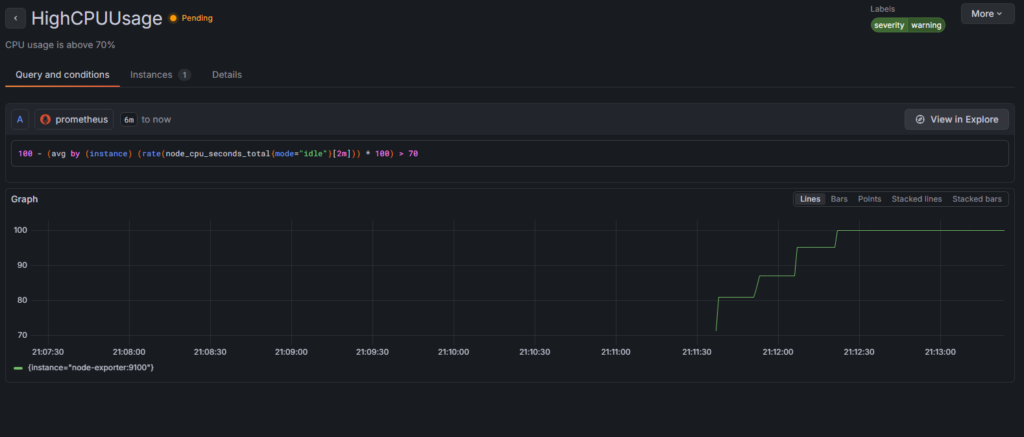
En Grafana (principal):
- Ir al dashboard Node Exporter Full
- Ver el gráfico de CPU subir en tiempo real
- Click en 🔔 Alerting → Alert rules
- Esperar 2 minutos (el
for: 2mde la regla) - Ver HighCPUUsage cambiar:
Inactive→Pending→Firing🔥
Opcional – En Prometheus:
- Si configuraste el puerto, ir a
http://TU_IP:9090/alerts(olocalhost:9090/alerts) - Ver la alerta cambiar de estado
Opcional – En Alertmanager:
- Si configuraste el puerto, ir a
http://TU_IP:9093(olocalhost:9093) - Ver la alerta listada
Paso 10: Crear tu Propio Dashboard Simple
- En Grafana: ☰ → Dashboards → New → New Dashboard
- Click Add visualization
- Seleccionar Prometheus como data source
- En la query escribir:
100 - (avg by(instance) (rate(node_cpu_seconds_total{mode="idle"}[5m])) * 100)
- En el panel de la derecha:
- Title: CPU Usage %
- Unit: Percent (0-100)
- Click Apply
- Save dashboard (icono 💾) → Nombre: «Mi Dashboard»
¡Felicidades! Acabas de crear tu primer panel personalizado
🧪 Pruebas Funcionales
✅ Checklist de Validación
Ejecuta estas pruebas para confirmar que todo funciona:
# 1. Verificar que todos los contenedores están corriendo
docker-compose ps
# Todos deben estar "Up"
# 2. Verificar que Prometheus recolecta métricas
curl -s http://localhost:9090/api/v1/targets | grep -o '"health":"[^"]*"'
# Debe mostrar: "health":"up"
# 3. Verificar que Node Exporter expone métricas
curl -s http://localhost:9100/metrics | grep node_cpu
# Debe mostrar líneas con métricas de CPU
# 4. Verificar reglas de alertas
curl -s http://localhost:9090/api/v1/rules | grep -o '"name":"[^"]*"'
# Debe mostrar los nombres de tus alertas
# 5. Verificar conectividad Grafana → Prometheus
# Desde el navegador: Grafana → Data sources → Prometheus → Test
# Debe decir "Data source is working"
🎯 Escenarios de Prueba
Escenario 1: Alerta de CPU Alta
# Generar carga
stress --cpu 4 --timeout 180s
# Esperar 2 minutos
# Verificar en http://TU_IP:9090/alerts
# Debe activarse HighCPUUsage
Escenario 2: Alerta de Memoria Alta
# Generar consumo de RAM
stress --vm 2 --vm-bytes 1G --timeout 180s
# Verificar en Prometheus/alerts
# Debe activarse HighMemoryUsage
Escenario 3: Simular Servicio Caído
# Detener Node Exporter
docker-compose stop node-exporter
# Esperar 1 minuto
# Verificar alerta ServiceDown
# Volver a levantar
docker-compose start node-exporter
🐛 Troubleshooting
Problema: No puedo acceder a Grafana desde mi navegador
1. Verificar que el contenedor está corriendo:
docker-compose ps
# Debe mostrar "Up" en grafana
2. Verificar que el puerto está expuesto:
docker-compose ps grafana
# Debe mostrar: 0.0.0.0:3000->3000/tcp
3. Verificar firewall (si está activo):
sudo ufw status
# Si está activo:
sudo ufw allow 3000/tcp
4. Verificar configuración de red de VirtualBox:
- Con Puente: Verifica que la VM tiene IP (
hostname -I) y haz ping desde tu PC - Con NAT: Verifica que configuraste port forwarding 3000 → 3000
5. Ver logs si persiste el problema:
docker-compose logs grafana
Problema: Contenedores no inician
# Ver logs detallados
docker-compose logs
# Verificar sintaxis de archivos
docker-compose config
# Reiniciar todo
docker-compose down
docker-compose up -d
Problema: Prometheus no muestra métricas
# Verificar targets
curl http://localhost:9090/api/v1/targets
# Verificar conectividad entre contenedores
docker-compose exec prometheus ping node-exporter
# Ver logs de Prometheus
docker-compose logs prometheus | grep error
Problema: Alertas no se disparan
# Verificar que las reglas se cargaron
curl http://localhost:9090/api/v1/rules
# Verificar sintaxis del archivo de reglas
docker-compose exec prometheus promtool check rules /etc/prometheus/alert.rules.yml
# Recargar configuración de Prometheus
curl -X POST http://localhost:9090/-/reload
Problema: Dashboard de Grafana en blanco
- Verificar que el data source de Prometheus está configurado correctamente
- Verificar que Prometheus tiene datos:
http://TU_IP:9090/graph - Ejecutar una query manual:
uponode_cpu_seconds_total - Verificar el rango de tiempo del dashboard (arriba a la derecha)
📊 Queries PromQL Útiles
Copia estas queries para explorar métricas:
# CPU usage por core
rate(node_cpu_seconds_total{mode!="idle"}[5m])
# CPU usage total
100 - (avg by(instance) (rate(node_cpu_seconds_total{mode="idle"}[5m])) * 100)
# Memoria disponible
node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes * 100
# Uso de disco
(node_filesystem_size_bytes - node_filesystem_free_bytes) / node_filesystem_size_bytes * 100
# Tráfico de red (recibido)
rate(node_network_receive_bytes_total[5m])
# Tráfico de red (enviado)
rate(node_network_transmit_bytes_total[5m])
# Procesos en ejecución
node_procs_running
# Load average
node_load1
node_load5
node_load15
# Uptime del sistema
node_time_seconds - node_boot_time_seconds
🎓 Conceptos Clave Aprendidos
1. Métricas vs Logs vs Traces
- Métricas (lo que usamos aquí): Datos numéricos agregados (CPU, RAM)
- Logs: Eventos discretos (errores, accesos)
- Traces: Flujo de requests (APM)
2. Pull vs Push
- Prometheus usa modelo Pull (él va a buscar las métricas)
- Ventaja: Control centralizado, no sobrecarga los servicios
3. Exporters
- Node Exporter: Sistema operativo
- MySQL Exporter: Bases de datos
- Blackbox Exporter: Endpoints HTTP
- Hay exporters para casi todo
4. PromQL (Prometheus Query Language)
- Lenguaje específico para consultar métricas
- Ejemplos:
up: Estado de targetsrate(): Tasa de cambiosum(),avg(),max(): Agregaciones
5. Alertas: Firing vs Resolved
- Pending: Condición se cumple pero aún no dispara
- Firing: Alerta activa
- Resolved: Condición ya no se cumple
🚀 Siguientes Pasos
Nivel 1: Mejoras Inmediatas
- [ ] Configurar persistencia de datos de Grafana
- [ ] Añadir más dashboards (hay miles en grafana.com)
- [ ] Configurar Alertmanager para enviar a Slack/Email
- [ ] Añadir autenticación más robusta
Nivel 2: Exporters Adicionales
- [ ] cAdvisor: Monitorear contenedores Docker
- [ ] Blackbox Exporter: Monitorear URLs/endpoints
- [ ] MySQL/PostgreSQL Exporter: Métricas de bases de datos
Nivel 3: Producción
- [ ] Configurar HTTPS con Nginx reverse proxy
- [ ] Implementar HA (High Availability) de Prometheus
- [ ] Configurar retention policies
- [ ] Integrar con servicios externos (PagerDuty, Opsgenie)
📚 Recursos Adicionales
Documentación Oficial
Dashboards Pre-hechos
- Grafana Dashboards
- Node Exporter Full: ID 1860
- Docker Monitoring: ID 193
- Prometheus Stats: ID 3662
Comunidad
🧹 Limpieza del Lab
Cuando termines de practicar:
# Detener y eliminar contenedores
docker-compose down
# Eliminar también los volúmenes (datos)
docker-compose down -v
# Eliminar archivos del proyecto
cd ~
rm -rf prometheus-stack
✅ Conclusión
Temas tratados:
✅ Stack de monitoreo funcional con 4 componentes
✅ Dashboards profesionales importados y personalizados
✅ Alertas configuradas y probadas en tiempo real
✅ Entendimiento de la arquitectura de Prometheus
✅ Queries PromQL para explorar métricas
Aplicación Real:
Este mismo stack (con ajustes) se usa en producción en miles de empresas para:
- Monitorear infraestructura (servidores, K8s)
- Detectar problemas antes que los usuarios
- Generar reportes de SLOs/SLIs
- Troubleshooting en tiempo real
Versión: 1.0
Última actualización: Diciembre 2025
Tomás Pardellas