El panorama tecnológico actual, caracterizado por arquitecturas distribuidas, microservicios, contenedores y funciones sin servidor, ha llevado al concepto tradicional de monitorización a sus límites. Mientras que la monitorización se ha centrado históricamente en responder a preguntas conocidas sobre el estado y el rendimiento de sistemas individuales —¿está caído el servidor X?, ¿la CPU está por encima del 80%?—, el entorno moderno exige una comprensión mucho más profunda y contextual. Este artículo explora el viaje desde la monitorización reactiva hacia un enfoque proactivo y exploratorio: la observabilidad, un verdadero cambio de paradigma en la gestión de sistemas complejos.
La monitorización tradicional, aunque sigue siendo valiosa para métricas de salud básicas y alertas sobre umbrales predefinidos, se basa en la premisa de que conocemos los fallos potenciales y podemos instrumentar nuestros sistemas para detectarlos. Se centra en los «conocidos conocidos»: métricas de rendimiento (CPU, memoria, I/O de disco, latencia de red), disponibilidad de servicios y errores de aplicación. Las herramientas de monitorización nos permiten configurar paneles de control y alertas para estas métricas, lo que es efectivo para identificar problemas cuya naturaleza ya anticipamos. Sin embargo, en un sistema donde los componentes interactúan dinámicamente, donde las dependencias son profundas y donde las fallas pueden surgir de interacciones inesperadas, la monitorización por sí sola genera puntos ciegos significativos.
La complejidad inherente a los sistemas distribuidos modernos —con sus múltiples capas de abstracción, comunicación asíncrona, bases de datos políglotas y servicios de terceros— hace que sea casi imposible predefinir todos los escenarios de falla. Un problema de rendimiento en un microservicio podría ser la consecuencia de una latencia en la base de datos, un cuello de botella en la red, un problema de concurrencia en otro servicio o incluso un pico de carga inesperado. Sin la capacidad de correlacionar y contextualizar la información a través de todo el grafo de servicios, la resolución de incidentes se convierte en un ejercicio tedioso de depuración manual y conjeturas, extendiendo el MTTR (Mean Time To Resolution) de manera inaceptable.
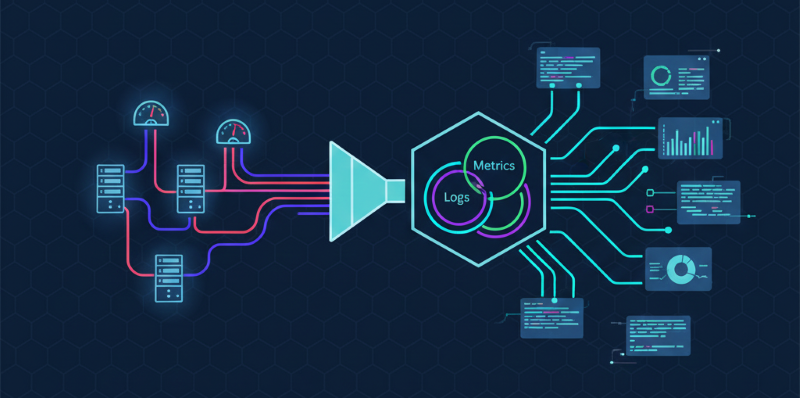
Es aquí donde la observabilidad emerge como la evolución necesaria. Inspirada en la teoría de control, la observabilidad es la capacidad de inferir el estado interno de un sistema basándose únicamente en sus salidas externas. Para sistemas de software, esto se traduce en la capacidad de hacer preguntas arbitrarias sobre el sistema en cualquier momento, sin tener que desplegar nuevo código o instrumentación. La observabilidad se construye sobre tres pilares fundamentales, a menudo conocidos como los «tres pilares de la observabilidad»:
- Métricas: Series temporales numéricas que representan una medida de algún aspecto del sistema en un momento dado. A diferencia de las métricas de monitorización básicas, las métricas de observabilidad suelen ser más ricas, con etiquetas o dimensiones que permiten un análisis granular (ej., latencia por servicio, por endpoint, por región, por versión).
- Logs: Registros de eventos discretos que ocurren dentro de una aplicación o servicio. Los logs de observabilidad van más allá de los mensajes de error básicos, incorporando datos estructurados (JSON, key-value) que proporcionan un contexto rico sobre el evento, el usuario, la transacción y el entorno.
- Traces (Trazas distribuidas): Representan la trayectoria de una solicitud a medida que fluye a través de múltiples servicios en una arquitectura distribuida. Cada operación dentro de la solicitud genera un «span», y la colección de spans relacionados forma una traza completa, permitiendo visualizar y analizar el flujo de ejecución, identificar cuellos de botella y comprender las dependencias entre servicios.
La diferencia clave entre monitorización y observabilidad radica en su propósito y alcance. La monitorización responde a «qué está pasando» en términos de métricas predefinidas, mientras que la observabilidad busca responder a «por qué está pasando» y «cómo se relaciona con todo lo demás», incluso para problemas imprevistos. Este observabilidad paradigma no se trata solo de recolectar más datos, sino de la capacidad de correlacionar, analizar y explorar esos datos de manera ad-hoc para entender el comportamiento del sistema en su totalidad.
Para administradores de sistemas y profesionales DevOps, la adopción de este nuevo paradigma ofrece un valor estratégico inmenso. Permite una depuración más rápida y eficiente, reduciendo significativamente el MTTR. Facilita la identificación proactiva de anomalías y tendencias antes de que escalen a incidentes críticos. Mejora la colaboración entre equipos de desarrollo y operaciones al proporcionar un lenguaje común y una visión compartida del estado del sistema. Además, impulsa una cultura de mejora continua al proporcionar la visibilidad necesaria para optimizar el rendimiento, la capacidad y la resiliencia.
Implementar la observabilidad requiere un enfoque holístico. Implica instrumentar consistentemente las aplicaciones y la infraestructura, preferiblemente utilizando estándares abiertos como OpenTelemetry, para generar métricas, logs y trazas con la riqueza contextual necesaria. Estos datos deben ser centralizados en plataformas capaces de ingestar, almacenar y permitir la consulta y correlación de grandes volúmenes de información. Más allá de las herramientas, el verdadero desafío y oportunidad reside en cultivar una cultura que valore la introspección del sistema, que empodere a los equipos para explorar los datos y que utilice esos conocimientos para construir sistemas más robustos y confiables.
En conclusión, en la era de la complejidad distribuida, la monitorización por sí sola ya no es suficiente. El viaje de la monitorización a la observabilidad no es simplemente una actualización de herramientas, sino un cambio fundamental en cómo entendemos, operamos y mejoramos nuestros sistemas. La adopción de este observabilidad paradigma es crucial para mantener la agilidad, la resiliencia y la excelencia operativa en el dinámico panorama tecnológico actual.
