En entornos modernos, la seguridad ya no puede ser un componente aislado ni reactivo. La detección temprana de anomalías en el tráfico de red y los patrones de acceso es crítica para prevenir incidentes graves y mitigar riesgos antes de que impacten la producción. Sin embargo, lograr esta capacidad requiere integrar la seguridad dentro de la observabilidad, aprovechando métricas, logs y trazas para obtener una visión holística y accionable.
Este artículo aborda cómo implementar una observabilidad de seguridad efectiva orientada a la detección temprana de anomalías en tráfico y accesos. Explicaremos conceptos clave, patrones de arquitectura para telemetría de seguridad, ejemplos prácticos con herramientas open source y comerciales, así como errores comunes que dificultan la detección o generan ruido innecesario.
Al finalizar, el lector contará con takeaways técnicos aplicables para diseñar y operar pipelines de telemetría que permitan detectar anomalías de seguridad con mayor precisión y velocidad, mejorando la postura defensiva de sus sistemas distribuidos.
Conceptos clave y contexto estratégico
La observabilidad de seguridad consiste en instrumentar sistemas para recolectar, correlacionar y analizar telemetría relevante a la seguridad, incluyendo tráfico de red, accesos, autenticaciones, autorizaciones y eventos de sistema. Esta telemetría debe ser procesada en tiempo real o casi real para detectar desviaciones que indiquen amenazas o comportamientos anómalos.
Los principales retos son:
- Volumen y variedad: la telemetría de seguridad puede generar grandes cantidades de datos heterogéneos, desde logs de autenticación hasta métricas de firewall o trazas de red.
- Contextualización: distinguir entre actividad legítima y maliciosa requiere correlacionar datos de diferentes fuentes y entender el contexto operacional.
- Detección temprana: identificar patrones anómalos antes de que se conviertan en incidentes críticos exige modelos adaptativos y alertas precisas.
En este sentido, la observabilidad moderna aporta un enfoque integral basado en métricas, logs y trazas, combinados con análisis avanzado (machine learning, reglas heurísticas) y arquitecturas escalables para ingestión y procesamiento.
Implementación práctica: arquitectura y configuración
Una arquitectura típica para observabilidad de seguridad orientada a detección temprana incluye:
- Agentes y collectors que recolectan telemetría desde endpoints, firewalls, proxies, sistemas de autenticación y aplicaciones.
- Pipeline de procesamiento que normaliza, enriquece (por ejemplo, con metadatos de usuario o geolocalización) y almacena la telemetría.
- Motor de análisis que ejecuta detección de anomalías mediante reglas, modelos estadísticos o AI.
- Visualización y alertas para que equipos de SRE y seguridad puedan investigar y responder rápidamente.
Un ejemplo básico usando OpenTelemetry Collector para recolectar logs de autenticación y métricas de tráfico podría ser:
receivers:
filelog:
include:
- /var/log/auth.log
start_at: end
prometheus:
config:
scrape_configs:
- job_name: 'firewall'
static_configs:
- targets: ['firewall.local:9100']
processors:
batch:
exporters:
otlp:
endpoint: telemetry-backend:4317
tls:
insecure: true
service:
pipelines:
logs:
receivers: [filelog]
processors: [batch]
exporters: [otlp]
metrics:
receivers: [prometheus]
processors: [batch]
exporters: [otlp]
Este pipeline recoge logs de autenticación y métricas de firewall, las procesa en lotes para eficiencia y las exporta a un backend compatible OTLP para análisis centralizado.
En el backend, por ejemplo con Elastic Stack, se pueden definir reglas de detección temprana basadas en agregaciones y correlaciones. Un query de Elasticsearch para detectar múltiples intentos fallidos de acceso desde una misma IP en 5 minutos podría ser:
POST /security-logs/_search
{
"query": {
"bool": {
"must": [
{ "match": { "event.action": "login_failure" } },
{
"range": {
"@timestamp": {
"gte": "now-5m"
}
}
}
]
}
},
"aggs": {
"by_ip": {
"terms": {
"field": "source.ip",
"min_doc_count": 10
}
}
}
}
Esto identifica IPs con al menos 10 fallos de login en 5 minutos, una señal común de ataque de fuerza bruta.
Detección de anomalías con Prometheus y PromQL
Para métricas de tráfico, Prometheus permite definir alertas basadas en desviaciones estadísticas. Por ejemplo, para detectar un aumento inusual en conexiones TCP desde una IP:
# Alert if connections from an IP superan 3x la media de las últimas 30m
avg_over_time(tcp_connections_total[30m]) * 3 < tcp_connections_total
Combinando con etiquetas (labels) que identifiquen IPs o usuarios, se pueden generar alertas específicas para tráfico sospechoso.
Casos de uso reales
En una plataforma de servicios financieros con alta regulación, se implementó un pipeline de observabilidad de seguridad con OpenTelemetry y Elastic Stack para detectar accesos no autorizados a APIs críticas. Se instrumentaron logs de autenticación, métricas de firewall y trazas de gateway API. Gracias a la correlación en Elastic y alertas basadas en patrones de acceso fuera de horario laboral o desde ubicaciones inusuales, se detectaron intentos de acceso comprometidos que fueron bloqueados antes de causar daño.
En otro caso, un equipo de SRE en una empresa SaaS utilizó Dynatrace para monitorizar tráfico y accesos. Aprovecharon la inteligencia artificial Davis AI para detectar patrones anómalos en el tráfico de red y accesos a bases de datos. La integración con workflows automatizados permitió iniciar procesos de contención (como bloqueo de IPs) en minutos. La ventaja fue la reducción significativa del ruido de alertas gracias a la correlación automática y la contextualización de eventos.
Errores comunes y antipatrones
Un error frecuente es recolectar telemetría sin un plan claro de análisis, lo que genera grandes volúmenes de datos difíciles de procesar y altos costos. Sin objetivos definidos, la detección de anomalías se vuelve imprecisa y genera alertas falsas o ignoradas.
Otro antipatón es no correlacionar fuentes de datos. Por ejemplo, analizar logs de acceso sin considerar métricas de red o trazas de aplicación limita la capacidad de detectar ataques sofisticados que combinan múltiples vectores.
Además, configurar reglas estáticas sin revisarlas ni ajustarlas al contexto operativo puede generar alertas irrelevantes. La seguridad es dinámica, por lo que los modelos de detección deben evolucionar con el entorno.
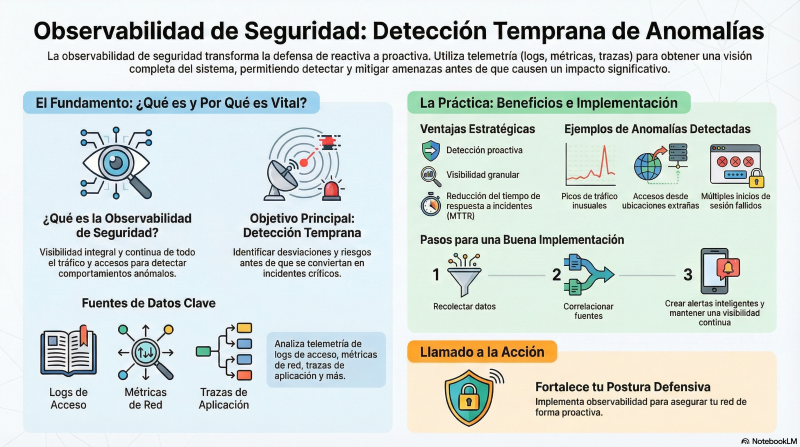
Buenas prácticas y recomendaciones
Para maximizar la efectividad de la observabilidad de seguridad en detección temprana:
- Definir claramente qué anomalías son relevantes para el negocio y priorizar la telemetría asociada.
- Implementar pipelines de telemetría escalables y normalizados para facilitar la correlación y análisis.
- Combinar métricas, logs y trazas para obtener un contexto completo y evitar falsos positivos.
- Utilizar modelos adaptativos o AI para detectar patrones no triviales, pero complementarlos con reglas heurísticas para transparencia.
- Integrar alertas con workflows de respuesta automática o semiautomática para acelerar la mitigación.
- Revisar y ajustar periódicamente las reglas y modelos de detección conforme cambian los patrones de tráfico y amenazas.
Para resumir
La observabilidad de seguridad orientada a la detección temprana de anomalías en tráfico y accesos es una capa indispensable para proteger sistemas distribuidos modernos. Integrar métricas, logs y trazas en pipelines robustos permite correlacionar eventos y detectar patrones sospechosos con mayor precisión y rapidez.
Los SREs y arquitectos de observabilidad deben diseñar estas soluciones con foco en escalabilidad, contexto y adaptabilidad, evitando la sobrecarga de datos y el ruido de alertas. Herramientas open source como OpenTelemetry, Prometheus y Elastic Stack, junto con plataformas comerciales como Dynatrace, ofrecen capacidades complementarias para abordar estos desafíos.
Como próximos pasos, recomiendo profundizar en técnicas avanzadas de análisis de series temporales para anomalías, integración de telemetría de red a nivel de paquete y la automatización de respuestas basadas en detección. La seguridad observacional es un campo en evolución que exige actualización constante y colaboración entre equipos de SRE, seguridad y desarrollo.
Ver este contendio en Youtube : https://youtu.be/-TIjC6Fl5Ik
