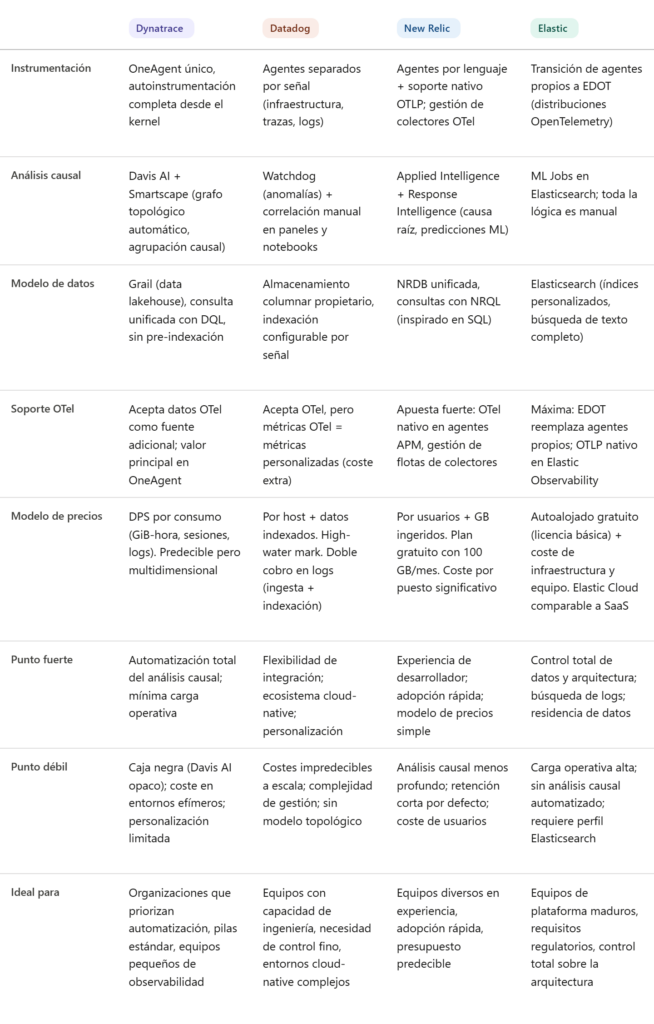
Cuando un equipo de plataforma se enfrenta a la decisión de adoptar una solución APM comercial, el proceso suele comenzar con una matriz de características y terminar con una negociación de costes. Entre medias, sin embargo, está la parte que realmente importa: entender qué arquitectura de observabilidad necesitas construir, qué compensaciones operativas estás dispuesto a aceptar, y qué capacidades críticas no puedes delegar en una plataforma externa. La elección entre Dynatrace, Datadog, New Relic o Elastic no es una cuestión de funcionalidades en una lista de comprobación, sino de modelos operativos incompatibles entre sí.
Cada una de estas plataformas representa un enfoque diferente sobre cómo debe funcionar la observabilidad en producción. Dynatrace apuesta por la automatización profunda y la inteligencia causal integrada. Datadog prioriza la flexibilidad de integración y la personalización mediante código. New Relic se centra en la experiencia de desarrollador y la simplicidad de adopción. Elastic ofrece control total sobre los datos y la arquitectura, a cambio de responsabilidad operativa completa. Ninguna es objetivamente superior: son modelos distintos que encajan en contextos organizativos y técnicos diferentes.
Una comparativa verdaderamente exhaustiva de estas plataformas requeriría un libro entero, no un artículo. El objetivo aquí es ofrecer una panorámica honesta de las diferencias arquitectónicas y operativas más relevantes, identificar los puntos fuertes y débiles de cada enfoque, y sobre todo, dar al lector los criterios para investigar por su cuenta cuál encaja mejor en su contexto. Las impresiones aquí recogidas se basan en experiencia real operando estas herramientas, no en demos comerciales. Cada organización debería hacer sus propias cuentas, probar las plataformas mediante pruebas de concepto limitadas con datos reales, y tomar la decisión en función de sus necesidades concretas.
Modelos de instrumentación y arquitectura de agentes
La primera diferencia estructural entre estas plataformas aparece en cómo capturan telemetría. Dynatrace despliega OneAgent, un componente único que instrumenta automáticamente aplicaciones, infraestructura, red y experiencia de usuario desde el kernel hacia arriba. Este modelo tiene una ventaja operativa clara: despliegas un único artefacto y obtienes correlación automática entre todas las capas de la pila tecnológica sin configuración adicional. La compensación es que delegas completamente la lógica de instrumentación en Dynatrace, lo que funciona muy bien en pilas tecnológicas convencionales pero puede ser limitante en arquitecturas muy específicas o experimentales.
Datadog utiliza un modelo de agentes especializados por tipo de telemetría: el Datadog Agent para métricas e infraestructura, bibliotecas de trazado específicas por lenguaje, y colectores separados para logs. Esta arquitectura ofrece más flexibilidad para personalizar qué se captura y cómo, pero requiere gestionar múltiples flujos de telemetría y resolver manualmente la correlación entre señales. En entornos con requisitos de personalización profunda o integraciones no estándar, este modelo da más control. En organizaciones grandes con equipos heterogéneos, puede generar fragmentación operativa.
New Relic ha evolucionado hacia un modelo híbrido que combina agentes de lenguaje tradicionales con soporte nativo para OpenTelemetry. Su apuesta por OTLP como protocolo nativo es significativa: permite usar instrumentación estándar y reducir la dependencia del proveedor a nivel de SDK. En febrero de 2026, New Relic lanzó herramientas específicas de OpenTelemetry que integran capacidades OTel directamente en sus agentes APM, además de ofrecer gestión de flotas de colectores OTel. Sin embargo, la experiencia más completa de New Relic sigue dependiendo de sus agentes propietarios para capacidades avanzadas como el perfilado continuo o la detección automática de anomalías. Es un equilibrio pragmático entre apertura y diferenciación comercial.
Elastic APM ha evolucionado significativamente su modelo de instrumentación. Históricamente utilizaba agentes APM propios (Java, Python, Node.js, Go, Ruby) que, aunque de código abierto bajo licencia Elastic, eran componentes específicos del ecosistema Elastic, no proyectos de la comunidad OpenTelemetry. Desde 2024, Elastic ha apostado de forma decidida por OpenTelemetry a través de sus distribuciones EDOT (Elastic Distributions of OpenTelemetry): versiones personalizadas de los SDK de OpenTelemetry con configuraciones optimizadas para Elastic Observability. La documentación oficial de Elastic ya recomienda EDOT como la vía principal de instrumentación, y los agentes APM clásicos serán retirados eventualmente, aunque sin fecha concreta. La compensación fundamental sigue siendo la misma: tú eres responsable de mantener la infraestructura de ingesta, almacenamiento, indexación y consulta. Para equipos con capacidad operativa y requisitos específicos de residencia de datos o personalización profunda, Elastic es la opción más flexible. Para organizaciones que buscan reducir la carga operativa, es la más costosa en términos de tiempo de ingeniería.
OpenTelemetry como factor transversal
Antes de seguir comparando capacidades específicas, merece la pena detenerse en el elefante en la sala: OpenTelemetry. OTel es ya el segundo proyecto más activo de la CNCF después de Kubernetes, y aproximadamente la mitad de las organizaciones lo están usando o tienen planes activos de adopción. Esto cambia la dinámica competitiva porque, en teoría, permite separar la instrumentación del destino de los datos.
En la práctica, cada plataforma maneja OpenTelemetry de forma diferente. Dynatrace acepta datos OTel como fuente adicional, pero su propuesta de valor principal sigue anclada en OneAgent y su modelo topológico automático: si usas solo OTel, pierdes parte de la magia de Smartscape y Davis AI. Datadog acepta datos OTel, pero clasifica las métricas de OpenTelemetry como «métricas personalizadas» con coste adicional, lo que puede generar facturas inesperadas si no se configura el filtrado correctamente. New Relic está haciendo la apuesta más agresiva por OTel entre las plataformas comerciales, integrando capacidades OTel directamente en sus agentes y ofreciendo gestión de colectores como servicio. Elastic va más lejos aún: está reemplazando directamente sus agentes propios por distribuciones de OpenTelemetry (EDOT).
Para el lector que evalúa plataformas hoy, la pregunta no es si OTel importa (importa), sino cuánto depende tu inversión a largo plazo de la instrumentación propietaria de cada proveedor. Instrumentar con OpenTelemetry y evaluar dos o tres destinos de datos con tráfico real de producción es probablemente el enfoque más sensato para tomar una decisión informada.
Análisis causal y gestión de problemas
La diferencia más significativa entre estas plataformas no está en qué datos capturan, sino en qué hacen con ellos una vez capturados. Aquí es donde los modelos divergen radicalmente.
Dynatrace construye automáticamente un grafo de dependencias en tiempo real (Smartscape) que modela relaciones causales entre servicios, procesos, hosts, contenedores y experiencia de usuario. Su motor Davis AI analiza este grafo continuamente para detectar anomalías, identificar causas raíz y agrupar síntomas relacionados en problemas únicos. Este enfoque reduce drásticamente el ruido: en lugar de recibir cientos de alertas correlacionadas, recibes un problema con su causa raíz probable y el impacto medido en usuarios o transacciones de negocio. La compensación es que confías en un modelo de IA propietario cuya lógica interna no puedes auditar ni modificar. Funciona bien en la mayoría de casos, pero cuando falla, investigar la causa raíz, lleva su tiempo como en otras plataformas.
Datadog ofrece capacidades de correlación manual mediante paneles, notebooks y su lenguaje de consulta. Puedes construir vistas que cruzan métricas, trazas y logs, pero la lógica de análisis causal la implementas tú mediante consultas y visualizaciones. Watchdog, su sistema de detección de anomalías, identifica patrones inusuales y ha ido incorporando capacidades de correlación automática (Watchdog Insights, análisis de causa raíz en APM), pero no construye un modelo topológico automático como Smartscape. Este enfoque da más control y transparencia: sabes exactamente qué lógica estás aplicando porque la has definido tú. La compensación es que requiere más esfuerzo de ingeniería para alcanzar un nivel comparable de automatización, y la calidad del análisis depende completamente de la experiencia del equipo.
New Relic ha evolucionado considerablemente en este terreno. Applied Intelligence agrupa alertas relacionadas, sugiere correlaciones y ofrece reducción automática de ruido. Pero la novedad más relevante es Response Intelligence, lanzado en 2025, que proporciona análisis causal, asistencia en la identificación de causa raíz y pasos de remediación contextualizados. También incorpora Predictions, que utiliza modelos de aprendizaje automático para anticipar problemas basándose en series temporales en lugar de limitarse a reaccionar ante umbrales. Según datos propios de New Relic, las cuentas con IA habilitada resuelven incidentes aproximadamente un 25% más rápido. La brecha con Davis AI sigue existiendo (Davis construye un grafo topológico automático que New Relic no replica de la misma forma), pero la distancia se ha acortado significativamente. Su fortaleza principal sigue siendo la experiencia de desarrollador: la interfaz está diseñada para que un ingeniero sin experiencia profunda en observabilidad pueda navegar desde un síntoma hasta código específico de forma intuitiva.
Elastic no ofrece análisis causal automatizado comparable fuera de la caja. Puedes construir detección de anomalías mediante Machine Learning Jobs de Elasticsearch, correlacionar señales mediante consultas complejas en Kibana, y diseñar paneles que crucen APM, logs y métricas. Pero toda la lógica de análisis la implementas tú. Para equipos con requisitos muy específicos o modelos de negocio únicos, esto puede ser una ventaja: puedes construir exactamente el análisis que necesitas. Para la mayoría de organizaciones, supone reconstruir capacidades que otras plataformas ofrecen de serie.
Modelos de datos y capacidades de consulta
La arquitectura de almacenamiento y consulta determina qué preguntas puedes responder en producción y a qué coste operativo. Aquí las diferencias son estructurales.
Dynatrace almacena telemetría en Grail, su data lakehouse diseñado específicamente para observabilidad, que unifica logs, métricas, trazas y eventos en un modelo consciente de la topología y en tiempo real. Su lenguaje DQL (Dynatrace Query Language) permite consultas complejas sobre todos los tipos de señal con sintaxis unificada. La ventaja principal de Grail es que elimina la necesidad de pre-agregar o pre-indexar datos: puedes consultar datos en bruto a velocidad interactiva sin haber decidido de antemano qué indexar. El modelo de datos está predefinido, lo que limita la flexibilidad pero garantiza rendimiento predecible. Casos de uso no estándar pueden requerir soluciones alternativas o ser directamente inviables.
Datadog utiliza un modelo de almacenamiento columnar propietario para métricas y un sistema de indexación configurable para logs y trazas. Puedes definir qué campos indexar, crear métricas derivadas y controlar la retención por tipo de dato. Este modelo da mucha flexibilidad para optimizar costes: puedes decidir qué trazas indexar completamente y cuáles muestrear agresivamente. La compensación es complejidad operativa: gestionar políticas de indexación, retención y muestreo requiere entender profundamente los patrones de acceso de tu organización. Un error en la configuración puede hacer que pierdas visibilidad crítica o que los costes se disparen.
New Relic almacena toda su telemetría en NRDB (New Relic Database), su base de datos unificada que almacena métricas, eventos, logs y trazas en un modelo común. Esto simplifica las consultas entre señales mediante NRQL, su lenguaje de consulta inspirado en SQL. El modelo es más rígido que el de Datadog pero más flexible que el de Dynatrace. La ventaja es coherencia: todas las señales se consultan de la misma forma. La limitación principal no es la capacidad de consulta en sí, sino la retención de datos: con el plan Original, la retención por defecto es de 8 días; con Data Plus, 90 días. Para investigaciones forenses que requieran datos históricos más allá de esos periodos, hay que negociar retención extendida con coste adicional.
Elastic ofrece control total porque tú gestionas los índices de Elasticsearch. Puedes diseñar esquemas personalizados, crear índices especializados por tipo de carga, implementar políticas complejas de gestión del ciclo de vida de los índices, y optimizar el particionado (sharding) según tus patrones de acceso. La capacidad de búsqueda de texto completo de Elasticsearch es difícil de igualar para volúmenes grandes de logs no estructurados. Esta flexibilidad es máxima, pero requiere experiencia profunda en Elasticsearch. Un clúster mal dimensionado o mal configurado degrada rápidamente bajo carga, y resolver problemas de rendimiento en Elasticsearch es un perfil técnico específico que no todos los equipos tienen.
Gestión de costes y modelos de precios
El coste real de una plataforma APM no está en el precio de lista, sino en cómo escala ese precio con tu crecimiento y cómo se comporta cuando necesitas capacidad adicional inesperadamente. Este es probablemente el área donde más diferencias encontrará cada organización según su contexto. Los precios indicados a continuación son orientativos y públicos a fecha de principios de 2026; siempre conviene verificarlos en la web oficial de cada proveedor y, sobre todo, negociar condiciones específicas.
Dynatrace ha evolucionado desde su modelo clásico de licenciamiento por Host Units hacia un modelo de suscripción basado en consumo llamado DPS (Davis Platform Subscription). El Full-Stack Monitoring se factura a $0,01 por GiB-hora de memoria del host, con un mínimo de 4 GiB por host. A esto se suman costes separados por sesiones RUM ($0,00225 por sesión), peticiones sintéticas ($0,001 por petición), logs ($0,20 por GiB ingerido) y otras dimensiones. Este modelo multidimensional es más preciso que el antiguo precio por host, pero también más complejo de predecir. El licenciamiento clásico sigue existiendo como opción para contratos heredados. La ventaja es que pagas por lo que realmente consumes; la compensación es que en arquitecturas cloud-native con alta rotación de contenedores, el coste puede crecer de forma no lineal. Hay descuentos por volumen y por contratos plurianuales.
Datadog cobra por host ($15-23/mes para infraestructura, $31/mes adicional para APM), contenedor, función serverless y volumen de datos indexados. Un detalle crítico que a menudo se pasa por alto: Datadog utiliza un sistema de facturación por marca de agua alta (high-water mark) que mide el recuento de hosts cada hora, descarta el 1% superior de horas, y factura el mes completo basándose en el pico siguiente. Esto significa que un escalado temporal de 5 días puede multiplicar la factura del mes entero. Además, la gestión de logs utiliza una tarificación en dos partes: la ingesta cuesta $0,10 por GB, pero para que los logs sean consultables hay que indexarlos, lo que cuesta $1,70 por millón de eventos. Este doble pago por el mismo dato es una de las trampas de coste más documentadas. La flexibilidad de control es máxima si tienes disciplina para gestionar las políticas de muestreo y filtrado, pero muchas organizaciones descubren que necesitan dedicar esfuerzo continuo solo a optimizar costes de Datadog.
New Relic utiliza un modelo basado en usuarios y volumen de datos ingeridos. El plan gratuito incluye 100 GB de ingesta mensual y un usuario de plataforma completa. Más allá de eso, la ingesta cuesta $0,40/GB con el plan Original ($0,60/GB con Data Plus, que incluye 90 días de retención y elegibilidad HIPAA/FedRAMP). Los usuarios adicionales de plataforma completa cuestan $99/mes en plan Standard (máximo 5) o $349/mes en plan Pro (ilimitados). Este modelo reduce la fricción de adopción y hace el coste más predecible que los modelos basados en infraestructura, pero el «impuesto por puesto» puede ser significativo en organizaciones grandes donde muchos ingenieros necesitan acceso. New Relic también está introduciendo un modelo alternativo de consumo basado en Core Compute (actualmente en vista previa pública) que podría aliviar esta limitación.
Elastic es gratuito si autoalojas con la licencia básica, pero el coste real está en infraestructura, operación y personal. Según estimaciones del mercado, gestionar 10 TB/mes de trazas y métricas autoalojando requiere entre $400-900/mes en infraestructura solo para los clústeres de Elasticsearch y Kibana. Elastic Cloud, la opción gestionada, maneja precios basados en consumo que pueden ser comparables a las alternativas comerciales (estimaciones de $2.500-3.000/mes para 10 TB de ingesta). Para organizaciones con equipos de plataforma maduros, el coste de autoalojar puede ser menor que las licencias comerciales. Para la mayoría, el coste oculto en tiempo de ingeniería supera ampliamente el ahorro en licencias.
Errores comunes en la evaluación y adopción
El error más frecuente es evaluar estas plataformas mediante demos con datos sintéticos en entornos de prueba. Las diferencias reales solo aparecen bajo carga de producción, con datos reales, y durante incidentes. Una plataforma que responde instantáneamente en la demo puede degradarse bajo consultas complejas sobre datos históricos. Un sistema de alertas que parece inteligente con tráfico simulado puede generar ruido insoportable con patrones de fallo reales. Lo ideal es realizar una prueba de concepto limitada con datos reales de producción: instrumentar un par de servicios representativos, generar carga real durante al menos dos semanas, y evaluar la experiencia durante un incidente (simulado si es necesario).
Otro error habitual es subestimar el coste de migración y la dependencia del proveedor. Cambiar de plataforma APM no es solo cambiar agentes: es reescribir paneles, recrear alertas, reentrenar equipos, y perder contexto histórico. Las organizaciones que tratan la decisión como reversible a corto plazo suelen descubrir que están comprometidas durante años. Esto no significa que la decisión sea irreversible, pero sí que debe tomarse asumiendo que cambiar tendrá un coste significativo. En este sentido, instrumentar con OpenTelemetry desde el principio reduce el acoplamiento a nivel de SDK, aunque no elimina la dependencia de los paneles, alertas y flujos de trabajo construidos sobre una plataforma concreta.
Un antipatrón recurrente es intentar replicar capacidades de una plataforma en otra mediante configuración manual. Equipos que migran entre plataformas a menudo intentan recrear la detección automática de problemas mediante alertas complejas y correlación manual. El resultado es frágil, costoso de mantener, y nunca alcanza la misma calidad. Cada plataforma tiene fortalezas arquitectónicas específicas: intentar forzar una a comportarse como otra es desperdiciar esfuerzo.
Finalmente, muchas organizaciones ignoran el factor humano. Una plataforma técnicamente potente que tu equipo no entiende o no quiere usar genera menos valor que una solución menos sofisticada que se adopta ampliamente. La curva de aprendizaje, la calidad de documentación, y la disponibilidad de experiencia en el mercado laboral son factores tan importantes como las capacidades técnicas.
Criterios de decisión según contexto organizativo
Dynatrace encaja mejor en organizaciones que priorizan automatización sobre control, que operan pilas tecnológicas relativamente estándar, y que valoran reducir la carga operativa del equipo de observabilidad. Es especialmente fuerte en entornos con alta complejidad de dependencias donde el análisis causal automatizado aporta valor inmediato. No es la mejor opción para startups con presupuesto limitado, arquitecturas experimentales, o equipos que necesitan personalización profunda de la instrumentación.
Datadog es idóneo para organizaciones que necesitan flexibilidad máxima de integración, que tienen capacidad de ingeniería para gestionar complejidad operativa, y que valoran la integración profunda con el ecosistema cloud-native. Su modelo de precios permite optimización agresiva de costes si tienes disciplina para implementarla. Requiere precaución si tu equipo es pequeño, si priorizas simplicidad operativa, o si necesitas análisis causal automatizado sin construirlo manualmente.
New Relic funciona bien en organizaciones que priorizan velocidad de adopción y experiencia de desarrollador, que tienen equipos con experiencia variada en observabilidad, y que valoran un modelo de precios predecible. Su apuesta por OpenTelemetry reduce el riesgo de dependencia del proveedor a largo plazo. Conviene evaluar bien el coste del modelo de usuarios si tu organización es grande y muchos perfiles necesitan acceso a los datos.
Elastic es la opción indicada para organizaciones con equipos de plataforma maduros, requisitos específicos de residencia de datos o cumplimiento regulatorio, y necesidad de control total sobre la arquitectura de observabilidad. También para casos de uso que requieren integración profunda entre APM, analítica de seguridad, y búsqueda empresarial. No es recomendable si tu equipo no tiene experiencia operando Elasticsearch a escala, si priorizas reducir la carga operativa, o si necesitas capacidades avanzadas de análisis causal sin construirlas desde cero.
Nota sobre Grafana Cloud: Merece mención como alternativa emergente la pila LGTM de Grafana Labs (Loki, Grafana, Tempo, Mimir), probablemente la opción más alineada con OpenTelemetry y código abierto del mercado. No cobra penalizaciones por métricas personalizadas ni por agentes propietarios, y su base de código abierto ofrece máxima portabilidad. Para equipos que han apostado estratégicamente por OpenTelemetry como estándar de instrumentación, merece una evaluación seria.
En definitiva, ninguna de estas plataformas es «la mejor» en abstracto. Cada una resuelve problemas diferentes con compensaciones diferentes. La recomendación más honesta es: haz tus propias cuentas, revisa los modelos de precios con datos reales de tu infraestructura, ejecuta una prueba de concepto limitada (dos o tres servicios, dos semanas de datos reales), e involucra a los equipos que realmente van a usar la herramienta en la evaluación. La decisión correcta depende de tu contexto, tu presupuesto, tu equipo y tus prioridades operativas.
Para seguir aprendiendo
Las siguientes referencias profundizan en aspectos arquitectónicos y estratégicos de las plataformas APM y la observabilidad moderna:
«Observability Engineering» de Charity Majors, Liz Fong-Jones y George Miranda (O’Reilly, 2ª edición 2025) — Perspectiva arquitectónica sobre cómo construir sistemas observables y qué capacidades necesitas de tus herramientas de telemetría. Enlace: https://www.oreilly.com/library/view/observability-engineering-2nd/9781098179915/
«The Site Reliability Workbook» de Betsy Beyer, Niall Richard Murphy, David K. Rensin, Kent Kawahara y Stephen Thorne (O’Reilly) — Casos prácticos de implementación de observabilidad en producción a escala, incluyendo criterios de selección de herramientas. Disponible gratuitamente: https://sre.google/workbook/table-of-contents/
Documentación de OpenTelemetry (OpenTelemetry Foundation, proyecto CNCF) — Especificación del estándar de telemetría que está redefiniendo cómo se instrumentan aplicaciones modernas. Enlace: https://opentelemetry.io/docs/
«Distributed Tracing in Practice» de Austin Parker, Daniel Spoonhower, Jonathan Mace, Ben Sigelman y Rebecca Isaacs (O’Reilly) — Análisis profundo de arquitecturas de trazado distribuido y cómo las diferentes plataformas implementan estos conceptos. Enlace: https://www.oreilly.com/library/view/distributed-tracing-in/9781492056621/
Documentación de Elastic Observability (Elastic) — Arquitectura de referencia para implementar observabilidad completa sobre Elasticsearch, incluyendo la transición a EDOT. Enlace: https://www.elastic.co/docs/solutions/observability
Plataformas oficiales para evaluación y pruebas de concepto:
- Dynatrace: https://www.dynatrace.com/trial/
- Datadog: https://www.datadoghq.com/free-datadog-trial/
- New Relic: https://newrelic.com/signup (plan gratuito permanente con 100 GB/mes)
- Elastic Observability: https://www.elastic.co/observability
- Grafana Cloud: https://grafana.com/products/cloud/
