En entornos Kubernetes gestionados como Amazon EKS, la observabilidad es clave para mantener la salud, rendimiento y confiabilidad de las aplicaciones y la infraestructura. OpenTelemetry Collector se ha consolidado como una pieza fundamental para recolectar, procesar y exportar datos de telemetría (métricas, trazas y logs) de forma flexible y escalable. En este artículo explicaremos qué es OpenTelemetry Collector, por qué es relevante en EKS, cómo implementarlo y configurarlo, y qué buenas prácticas seguir para construir un pipeline de telemetría moderno y eficiente.
¿Qué es OpenTelemetry Collector y por qué usarlo en EKS?
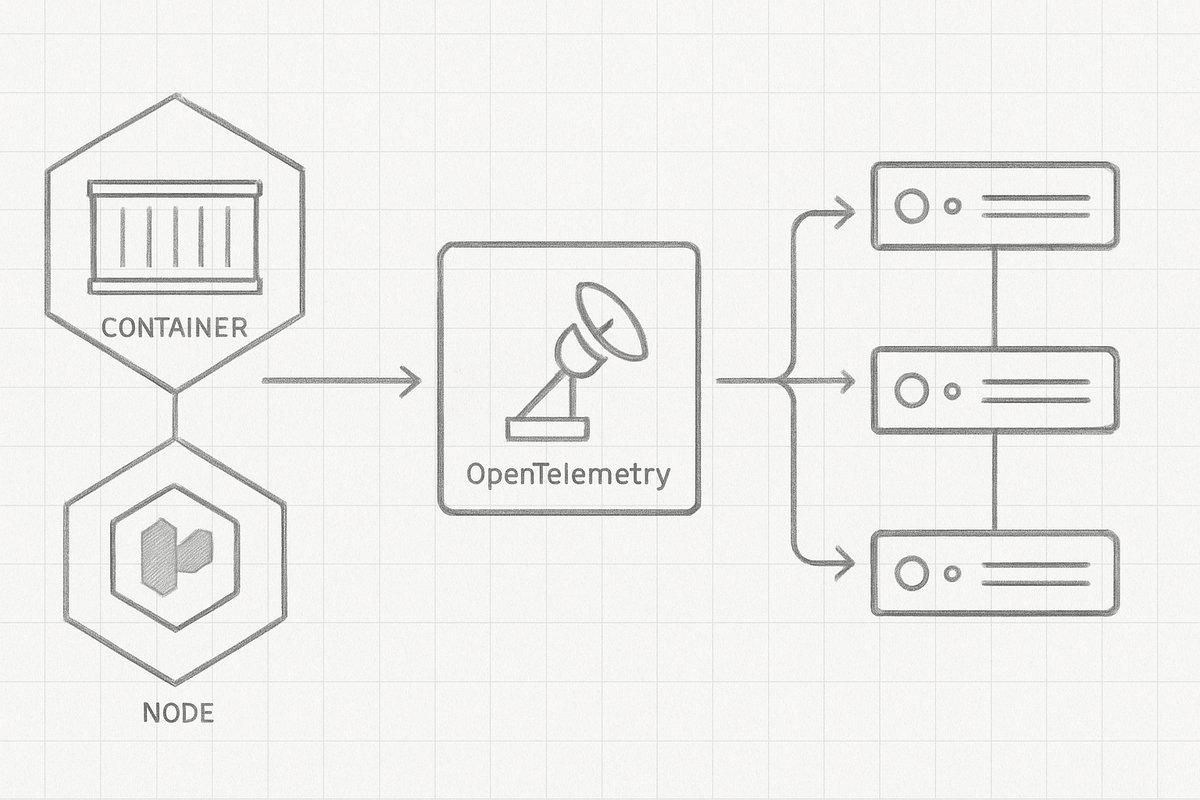
OpenTelemetry Collector es un componente independiente, desarrollado por la Cloud Native Computing Foundation (CNCF), que actúa como un agente o gateway para recibir, procesar y exportar datos de observabilidad. Su diseño modular permite integrar múltiples fuentes y destinos, normalizando datos de trazas, métricas y logs.
En el contexto de EKS, OpenTelemetry Collector aporta varias ventajas:
- Desacoplamiento: separa la recolección y procesamiento de telemetría de las aplicaciones, evitando sobrecargar los pods con agentes adicionales.
- Flexibilidad: soporta múltiples protocolos y formatos (OTLP, Jaeger, Prometheus, Zipkin, etc.) y puede exportar a diversas plataformas (Dynatrace, Elastic, Prometheus, Grafana Cloud, etc.).
- Escalabilidad y gestión centralizada: se puede desplegar como DaemonSet para colectar datos en cada nodo, o como Deployment para centralizar la ingesta y procesamiento.
- Procesamiento avanzado: permite aplicar filtros, agregaciones, enriquecimiento y transformación de datos antes de exportarlos.
Esto lo convierte en una pieza clave para construir pipelines de observabilidad modernas en Kubernetes, donde la complejidad y la dinámica de los entornos requieren soluciones robustas y adaptables.
Arquitectura típica de OpenTelemetry Collector en EKS
En un clúster EKS, la implementación de OpenTelemetry Collector suele adoptar dos patrones principales:
1. Collector como DaemonSet
Se despliega un pod Collector en cada nodo del clúster. Esto permite colectar telemetría directamente desde las aplicaciones que corren en ese nodo, minimizando la latencia y la pérdida de datos.
2. Collector centralizado (Deployment)
Un único Collector o un conjunto de réplicas se ejecutan en el clúster para recibir datos desde agentes ligeros o directamente desde las aplicaciones. Este enfoque facilita el procesamiento y la exportación centralizada.
En la práctica, muchas organizaciones combinan ambos enfoques: un DaemonSet para la recolección local y un Collector centralizado para el procesamiento y exportación final.
Pasos para implementar OpenTelemetry Collector en EKS
A continuación se describen los pasos básicos para desplegar y configurar OpenTelemetry Collector en un clúster EKS, con un enfoque práctico y adaptable a distintos escenarios.
1. Preparar el clúster EKS
Antes de desplegar, asegúrate de tener configurado el acceso kubectl y permisos adecuados para crear recursos en el clúster. También es recomendable contar con un namespace dedicado para la observabilidad, por ejemplo:
kubectl create namespace observability2. Definir la configuración del Collector
El corazón del Collector es su archivo de configuración YAML, donde se definen:
- Receivers: protocolos y puertos para recibir datos (OTLP, Jaeger, Prometheus, etc.).
- Processors: filtros, agregadores, batchers para transformar datos.
- Exporters: destinos finales (Dynatrace, Elastic, Prometheus remote write, etc.).
- Service: la pipeline que conecta receivers, processors y exporters.
Ejemplo simplificado de configuración para recibir OTLP y exportar a un backend compatible OTLP:
receivers:
otlp:
protocols:
grpc:
http:
processors:
batch:
exporters:
otlp:
endpoint: "backend.telemetria.svc:4317"
tls:
insecure: true
service:
pipelines:
traces:
receivers: [otlp]
processors: [batch]
exporters: [otlp]
metrics:
receivers: [otlp]
processors: [batch]
exporters: [otlp]
3. Crear el deployment o DaemonSet en Kubernetes
Con la configuración lista, se crea un ConfigMap para el archivo de configuración y luego se despliega el Collector. Un ejemplo básico de DaemonSet:
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: otel-collector
namespace: observability
spec:
selector:
matchLabels:
app: otel-collector
template:
metadata:
labels:
app: otel-collector
spec:
containers:
- name: otel-collector
image: otel/opentelemetry-collector-contrib:latest
command:
- "/otelcontribcol"
- "--config=/conf/otel-collector-config.yaml"
volumeMounts:
- name: config-volume
mountPath: /conf
volumes:
- name: config-volume
configMap:
name: otel-collector-config
4. Instrumentar las aplicaciones y servicios
Para aprovechar el Collector, las aplicaciones deben enviar telemetría en formatos compatibles (por ejemplo, OTLP). Esto puede hacerse mediante SDKs OpenTelemetry en el código o mediante sidecars o agentes que recolecten datos y los envíen al Collector.
En Kubernetes, es común usar anotaciones para habilitar scraping de métricas Prometheus o configurar variables de entorno para que las aplicaciones exporten trazas a la dirección del Collector.
5. Validar y monitorear el pipeline
Una vez desplegado, se recomienda verificar que los datos fluyen correctamente hacia el backend. Se pueden revisar logs del Collector, métricas internas y dashboards en la plataforma de observabilidad para detectar errores o cuellos de botella.
Ejemplo real: integración de OpenTelemetry Collector con Dynatrace en EKS
Dynatrace es una plataforma de observabilidad que soporta la ingesta de datos OpenTelemetry. Un flujo típico en EKS podría ser:
- Desplegar OpenTelemetry Collector como DaemonSet para recibir métricas y trazas de aplicaciones instrumentadas.
- Configurar el Collector para exportar datos al endpoint OTLP de Dynatrace, usando el token de API para autenticación.
- Instrumentar aplicaciones con SDK OpenTelemetry para enviar datos al Collector local.
- Visualizar en Dynatrace dashboards, analizar trazas distribuidas, configurar alertas y definir SLOs basados en métricas recolectadas.
Este enfoque permite aprovechar la capacidad de detección automática de Dynatrace junto con la flexibilidad del Collector para integrar fuentes adicionales o aplicar procesamiento personalizado.
Buenas prácticas y errores habituales al implementar OpenTelemetry Collector en EKS
Buenas prácticas
- Separar responsabilidades: usar DaemonSet para la recolección local y Deployment para procesamiento centralizado cuando sea necesario.
- Gestionar recursos: asignar límites y requests adecuados para evitar que el Collector afecte la estabilidad del nodo o clúster.
- Seguridad: proteger endpoints y credenciales, usar TLS y autenticación para exportadores.
- Monitorizar el Collector: habilitar métricas internas para detectar pérdidas de datos o errores.
- Versionado y actualizaciones: mantener el Collector actualizado para beneficiarse de mejoras y correcciones.
Errores comunes
- Configuración incorrecta de receivers o exporters: puede causar pérdida de datos o fallos en la exportación.
- Falta de procesamiento: no usar procesadores puede generar altos volúmenes de datos innecesarios, afectando costos y rendimiento.
- Instrumentación incompleta: no instrumentar correctamente las aplicaciones limita la visibilidad.
- No validar el pipeline: no revisar logs ni métricas del Collector puede retrasar la detección de problemas.
Conclusión
Implementar OpenTelemetry Collector en Amazon EKS es una estrategia eficaz para construir pipelines de telemetría modernos, flexibles y escalables. Permite centralizar la recolección y procesamiento de métricas, trazas y logs, integrándose con múltiples plataformas de observabilidad como Dynatrace, Elastic o Prometheus. Siguiendo buenas prácticas en configuración, despliegue e instrumentación, se puede mejorar significativamente la visibilidad y el control sobre aplicaciones y la infraestructura Kubernetes.
Como próximos pasos, recomiendo explorar la integración con herramientas de visualización y alertas, definir SLOs basados en los datos recolectados, y automatizar despliegues del Collector dentro de flujos CI/CD para mantener consistencia y trazabilidad.
