
Llevo más de dos años trabajando con Dynatrace y, si algo he aprendido en este tiempo, es que la plataforma siempre ha ido un paso por delante en el uso de inteligencia artificial aplicada a la observabilidad. Davis, su motor de IA, lleva años haciendo análisis de causa raíz de forma determinística mientras otros vendors todavía vendían dashboards llenos de métricas que alguien tenía que interpretar manualmente. Pero lo que acaban de anunciar en Perform 2026 es, posiblemente, el movimiento más ambicioso que he visto en este sector.
Hablo de Dynatrace Intelligence, y merece que le dediquemos un rato a entender qué significa realmente.
De la observabilidad reactiva a las operaciones autónomas
Antes de entrar en materia técnica, pongamos contexto. La observabilidad, tal y como la conocemos hoy, sigue siendo fundamentalmente reactiva. Sí, tenemos alertas predictivas, sí, tenemos correlación automática de eventos, pero al final del día seguimos siendo nosotros los que tomamos las decisiones y ejecutamos las acciones. El sistema detecta, nosotros actuamos.
Lo que Dynatrace plantea con este anuncio es cambiar ese paradigma por completo. La idea es pasar de un modelo donde los humanos operan los sistemas digitales a uno donde los sistemas se operan solos bajo supervisión humana. Suena a ciencia ficción, pero cuando desgranas lo que han construido, empiezas a ver que quizás no estamos tan lejos.
Bernd Greifeneder, el CTO y fundador de Dynatrace, lo explica con una claridad que se agradece: las empresas están invirtiendo cantidades enormes en IA, pero la mayoría siguen atascadas en fase piloto sin conseguir resultados tangibles. Y el problema no es la tecnología en sí, sino cómo se está aplicando. Añadir agentes de IA a procesos legacy no funciona. Necesitas repensar cómo se toman las decisiones y cómo se automatizan las acciones desde cero.
El problema de las alucinaciones en sistemas críticos
Aquí es donde el anuncio de Dynatrace cobra especial relevancia. Cualquiera que haya trabajado con modelos de lenguaje grandes sabe que alucinan. Es su naturaleza. Son sistemas probabilísticos que generan respuestas basándose en patrones estadísticos, no en hechos verificados. Para escribir un email o resumir un documento, una alucinación ocasional es tolerable. Para decidir si escalar un cluster de Kubernetes o reiniciar un servicio crítico en producción, una alucinación puede significar una caída de servicio o, peor aún, una brecha de seguridad.
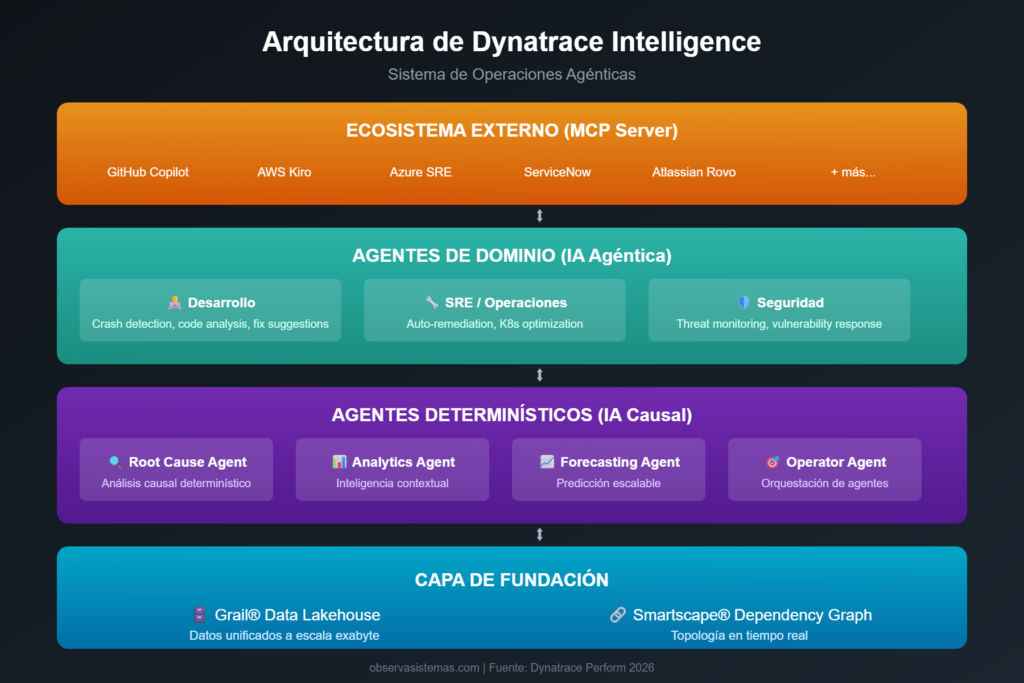
Dynatrace aborda este problema de una forma que me parece elegante: en lugar de confiar ciegamente en IA generativa, construyen un sistema híbrido donde la IA determinística hace el trabajo pesado y la IA agéntica se encarga del razonamiento y la planificación. Los agentes fundacionales que han presentado (Root Cause Agent, Analytics Agent, Forecasting Agent, Operator Agent) están diseñados para dar respuestas basadas en datos reales, no en probabilidades.
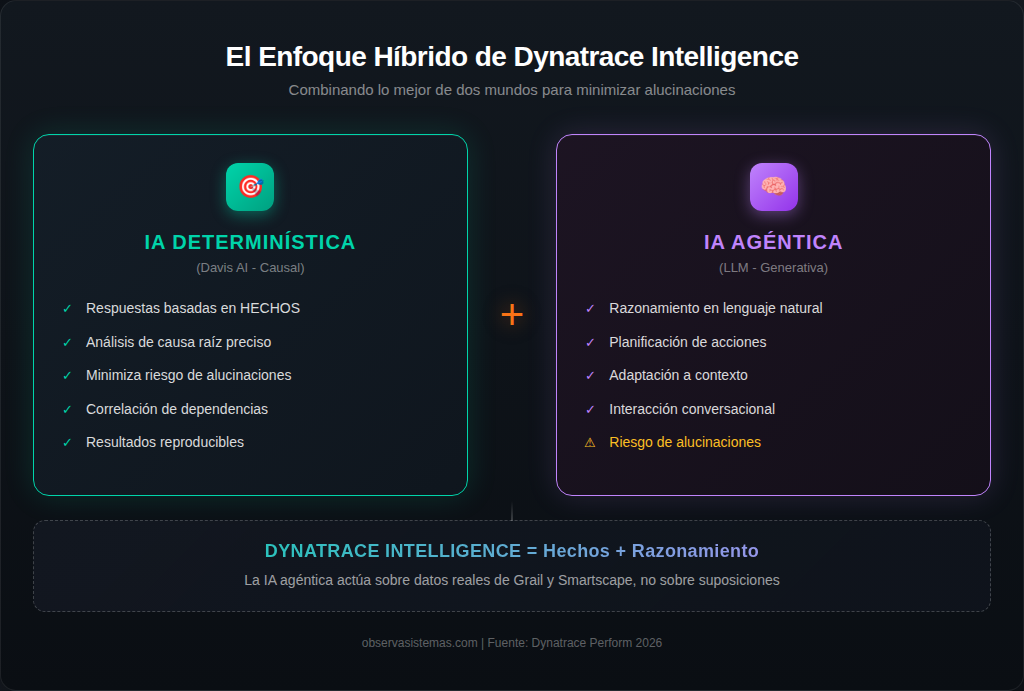
La clave está en Grail y Smartscape. Grail es su data lakehouse que unifica todos los datos de observabilidad a escala de exabytes. Smartscape es su grafo de dependencias en tiempo real que mapea cómo se relacionan todos los componentes de tu infraestructura. Juntos, proporcionan el contexto factual que los agentes necesitan para tomar decisiones informadas. Es como darle a la IA generativa un ancla a la realidad antes de que empiece a divagar.
Lo que realmente cambia en el día a día
Más allá de la arquitectura técnica, lo interesante es pensar cómo esto afecta al trabajo real de un equipo de operaciones o SRE. Dynatrace ha anunciado integraciones con prácticamente todo el ecosistema de herramientas modernas: GitHub Copilot, AWS Kiro, Azure SRE Agent, ServiceNow, Atlassian Rovo. La idea es que no tengas que saltar entre herramientas para entender qué está pasando.
Imagina este escenario: estás desarrollando en VS Code, detectas un comportamiento extraño en producción, y en lugar de abrir Dynatrace en otra pestaña, consultar logs, revisar trazas y correlacionar métricas, simplemente le preguntas a Copilot qué está pasando. El MCP Server de Dynatrace le proporciona todo el contexto de producción en tiempo real, incluyendo el análisis de causa raíz que Davis ya ha calculado, y te sugiere una solución. Todo sin salir de tu IDE.
O este otro: un agente de Azure detecta una degradación en tu infraestructura cloud, consulta a Dynatrace Intelligence para entender el impacto real en el negocio y las dependencias afectadas, y ejecuta automáticamente las acciones de remediación predefinidas. Tú recibes una notificación de que hubo un problema y ya está resuelto, con un informe detallado de qué pasó y por qué.
Suena bien, ¿verdad? Pero aquí es donde hay que poner los pies en el suelo.
Las preguntas incómodas que nadie hace
Después de leer todos los anuncios y la documentación disponible, me quedan varias reflexiones que creo importante compartir.
La primera es sobre la dependencia tecnológica. Si Dynatrace Intelligence se convierte en el cerebro que opera tu infraestructura, ¿qué pasa cuando Dynatrace tiene problemas? Ya hemos visto caídas de grandes plataformas cloud que arrastraron a miles de empresas. Cuanto más autónomo sea el sistema, más crítica se vuelve su disponibilidad. No es un argumento en contra de la tecnología, pero sí algo que hay que tener muy presente en el diseño de la arquitectura de resiliencia.
La segunda tiene que ver con las habilidades del equipo. He visto este patrón repetirse con cada salto tecnológico: la automatización elimina tareas repetitivas, pero también elimina las oportunidades de aprender haciendo. Un junior que nunca ha tenido que diagnosticar manualmente un problema de rendimiento porque el sistema lo hace solo, ¿desarrollará alguna vez la intuición necesaria para los casos edge que la IA no sabe manejar? Es un equilibrio delicado entre eficiencia y formación.
La tercera es más filosófica pero igualmente relevante: la confianza. Dynatrace habla de un modelo de supervisión humana donde los humanos definen objetivos y guardrails, y la IA ejecuta. Pero para que eso funcione, necesitas confiar en que la IA está haciendo lo correcto. Y esa confianza se construye con tiempo, transparencia y, sobre todo, con la capacidad de entender por qué el sistema tomó una decisión concreta. La explicabilidad de las decisiones de IA sigue siendo un reto sin resolver completamente.
Mi valoración personal
Dicho todo lo anterior, creo que lo que Dynatrace está construyendo representa un salto genuino en la evolución de la observabilidad. No es marketing vacío ni buzzwords apilados. Hay ingeniería real detrás, hay una visión coherente de hacia dónde va el sector, y hay una ejecución que, al menos sobre el papel, tiene sentido.
El enfoque híbrido de combinar IA determinística con IA agéntica me parece particularmente acertado. En lugar de subirse al carro de la IA generativa sin más y esperar que todo funcione, han identificado dónde cada tipo de IA aporta valor y han diseñado una arquitectura que aprovecha lo mejor de ambos mundos. La IA determinística para los hechos, la IA agéntica para el razonamiento. Simple en concepto, complejo en ejecución.
El roadmap de tres etapas (automatizado, autónomo supervisado, totalmente autónomo) también me parece realista. No están prometiendo que mañana tu infraestructura se va a operar sola. Están trazando un camino gradual donde cada organización puede avanzar a su ritmo, validando resultados en cada fase antes de dar más autonomía al sistema.
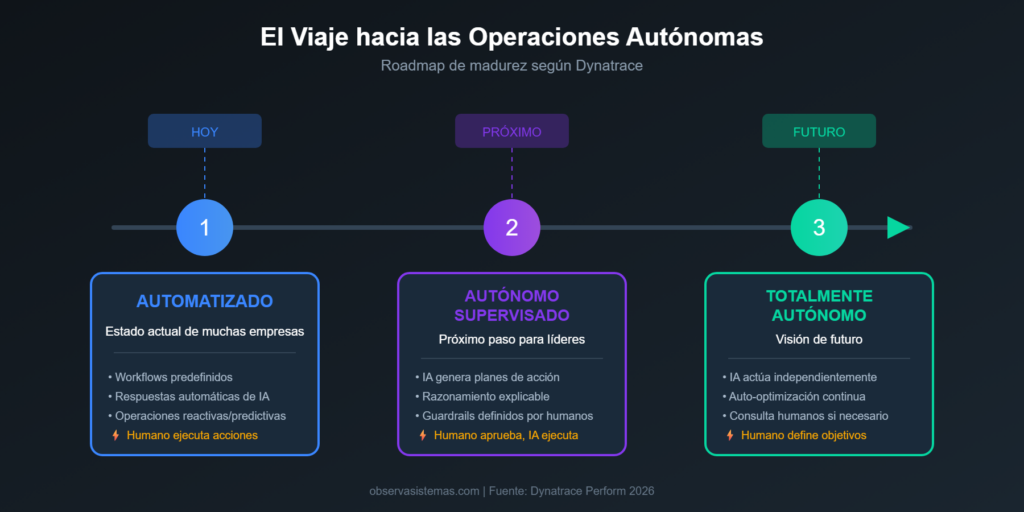
¿Es perfecto? No. ¿Hay riesgos? Sí. ¿Es el futuro de la observabilidad? Probablemente.
Resumiendo
Llevamos años hablando de AIOps como la próxima gran revolución, pero la realidad es que la mayoría de implementaciones se han quedado en dashboards bonitos con algo de machine learning por encima. Dynatrace Intelligence parece ser el primer intento serio de convertir esa promesa en realidad operativa.
Para los que trabajamos en este campo, los próximos meses van a ser interesantes. Habrá que ver cómo maduran estas capacidades en entornos de producción reales, qué casos de uso emergen como los más valiosos, y cómo responde el resto del mercado. Porque si Dynatrace ha marcado el camino, puedes estar seguro de que Datadog, Splunk, New Relic y compañía no van a quedarse mirando.
Mientras tanto, si tienes acceso a Dynatrace, te recomiendo que empieces a explorar el MCP Server y las nuevas capacidades de Dynatrace Assist. No hace falta esperar a la autonomía total para empezar a beneficiarse de estas mejoras. Y si no tienes acceso, al menos ya sabes hacia dónde se mueve el sector.
La observabilidad está dejando de ser solo observar. Está empezando a ser actuar. Y eso lo cambia todo.
Enlaces de interés:
- Artículo original del CEO de Dynatrace
- Documentación de Dynatrace Intelligence
- Dynatrace MCP Server en el Hub
