
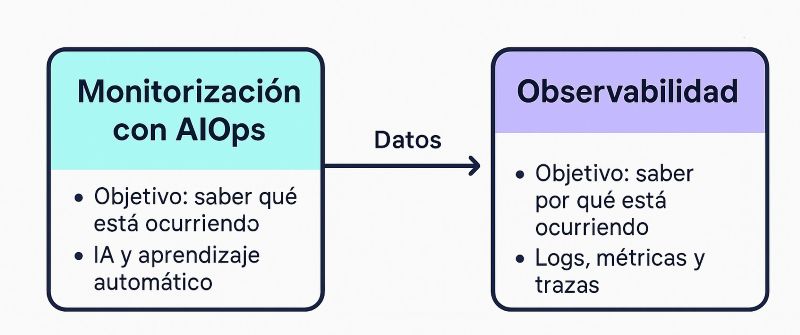
Observabilidad: Entender el «por qué»
La observabilidad es la capacidad de entender lo que ocurre dentro de un sistema complejo a partir de los datos que genera. No se trata solo de saber si algo está funcionando o no, sino de entender el comportamiento interno del sistema.
- Se basa en logs, métricas y trazas. (los tres pilares básicos)
- Permite realizar análisis de causa raíz.
- Es clave para entornos distribuidos y microservicios.
AIOps: Automatizar el «qué hacer»
AIOps (Artificial Intelligence for IT Operations) aplica inteligencia artificial y machine learning para mejorar y automatizar las operaciones de TI.
- Detecta anomalías, correlaciona eventos y predice fallos.
- Permite automatizar respuestas como reiniciar servicios o escalar recursos.
- Reduce el ruido de alertas y mejora el tiempo de resolución.
¿Cómo se relacionan?
- Observabilidad proporciona los datos y el contexto.
- AIOps los analiza y actúa sobre ellos de forma inteligente.
- Juntas permiten pasar de una monitorización reactiva a una gestión proactiva y automatizada.
Comparativa de herramientas del mercado
Aquí tienes una tabla con las principales herramientas que ofrecen observabilidad, AIOps o ambas:
| Herramienta | Enfoque Principal | Ideal Para | Capacidades AIOps / IA | Integraciones Destacadas | Fortalezas Clave |
|---|---|---|---|---|---|
| Dynatrace | Observabilidad full-stack + AIOps | Entornos complejos y empresariales | Davis AI (análisis raíz, automatización) | Auto-descubrimiento, LLM observability | Alta automatización, insights precisos |
| Datadog | Observabilidad cloud-native | Equipos DevOps y SRE | ML para correlación de alertas | +800 integraciones, seguridad, APM | Flexibilidad, escalabilidad, dashboards intuitivos |
| New Relic | APM + Observabilidad unificada | Equipos de desarrollo | Detección de anomalías, APM 360 | RUM, synthetics, infra, logs | Simplicidad, modelo de pago por uso |
| Splunk | Observabilidad + Seguridad (SIEM) | Empresas con foco en seguridad | SOAR, detección de anomalías | +1000 integraciones, SIEM | Análisis de logs + seguridad operativa |
| Grafana | Visualización + stack modular OSS | Equipos técnicos con experiencia | (en versión cloud) | Loki (logs), Tempo (trazas), Mimir (métricas) | Personalización, open-source, integración con Prometheus |
| BHOM (BMC Helix) | Observabilidad + AIOps empresarial | Grandes entornos híbridos y multi-cloud | GenAI, causal chain, auto-remediación | Discovery, CMDB, Intelligent Automation | Situational analysis, AI explicativa, automatización |
| AppDynamics | APM + Infraestructura | Grandes empresas | IA limitada (detección de anomalías) | Log Observer, Network Explorer | Profundidad en rendimiento de aplicaciones |
| Selector AI | Troubleshooting rápido con IA | Equipos pequeños o ágiles | NLP + correlación ML | Slack, dashboards personalizados | Simplicidad, insights rápidos, config observability |
¿Cómo aplicar esto en una infraestructura IT tradicional?
Si vienes de un entorno con herramientas de monitorización tradicional, donde la monitorización se basa en umbrales estáticos y alertas básicas, el salto hacia observabilidad y AIOps implica:
- Instrumentar tus sistemas con agentes que recojan logs, métricas y trazas.
- Adoptar herramientas modernas que integren observabilidad y AIOps.
- Definir modelos de servicio y políticas de correlación.
- Automatizar respuestas ante eventos comunes (reinicios, escalados, etc.).
- Formar al equipo en análisis de datos y gestión inteligente de operaciones.
Conclusión
La observabilidad y AIOps no son solo modas tecnológicas, sino formas modernas de entender y gestionar sistemas complejos. Adoptarlas permite a las organizaciones anticiparse a los problemas, reducir tiempos de resolución y mejorar la experiencia del usuario final.
Si estás en un equipo de IT y te preguntas cómo empezar, lo primero es entender estos conceptos, evaluar tu infraestructura actual y dar pasos progresivos hacia una gestión más inteligente y automatizada.
