Son las 2:47 de la madrugada y el equipo de guardia recibe una alerta: el tiempo de respuesta del proceso de pago ha subido un 300% en los últimos cuatro minutos. El SRE abre la plataforma de observabilidad y busca las trazas del flujo API Gateway → Checkout → Validación de tarjetas → Antifraude externo. No encuentra nada. El muestreo aleatorio configurado al 1% descartó exactamente esas transacciones. El incidente duró 23 minutos más de lo necesario porque no había datos de lo que importaba, aunque el sistema había procesado 47 millones de spans esa noche.
Este escenario no es una exageración. Es el problema central de la telemetría moderna: recoger demasiado de lo irrelevante y muy poco de lo que importa.
La telemetría adaptativa no es una herramienta concreta ni una especificación formal. Es un enfoque para recoger datos de observabilidad que ajusta dinámicamente qué se captura y con qué nivel de detalle, basándose en el contexto de lo que está ocurriendo en ese momento. La idea suena obvia cuando la escuchas: si todo va bien, no necesitas registrar cada petición HTTP con todos sus atributos. Pero cuando algo empieza a ir mal, necesitas toda la información posible sobre esas transacciones problemáticas específicas.
El problema es que tradicionalmente hemos trabajado con dos extremos igualmente insatisfactorios: o recoges todo y el coste se dispara, o muestreas de forma ciega y te pierdes lo importante. La telemetría adaptativa intenta resolver esta dicotomía siendo selectiva de forma inteligente.
Por qué el muestreo tradicional no es suficiente
Durante años, el muestreo estadístico ha sido la respuesta estándar al problema del volumen. Configuras tu instrumentación para capturar el 1% de las trazas, asumes que esa muestra es representativa, y listo. Funciona razonablemente bien cuando quieres entender patrones generales: latencias medias, throughput, distribución de errores.
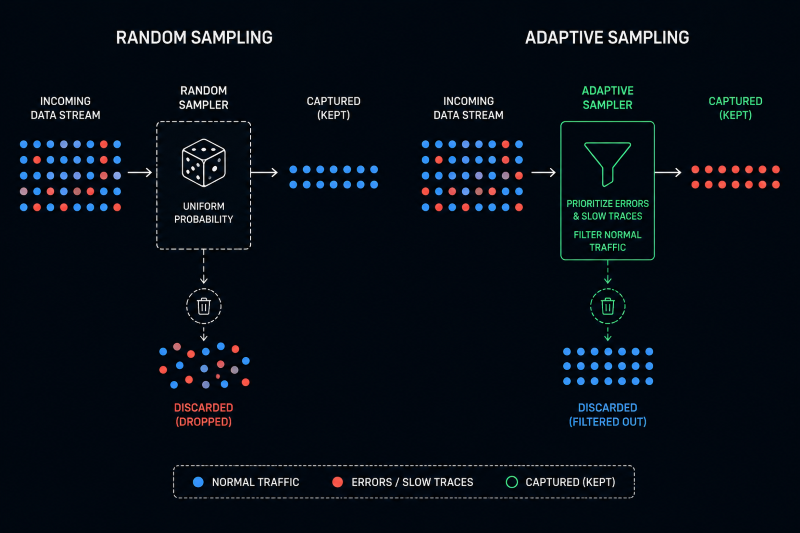
Pero falla estrepitosamente en el momento que más lo necesitas. Imagina que tienes un bug que afecta solo a usuarios con un tipo específico de suscripción, que representan el 0,5% de tu tráfico. Si estás muestreando al 1%, las probabilidades de capturar suficientes ejemplos de ese problema concreto son mínimas. Y si el problema solo ocurre bajo ciertas condiciones de carga o con combinaciones específicas de parámetros, el muestreo aleatorio es prácticamente inútil.
Hay otro problema más sutil: el muestreo tradicional trata todas las transacciones como iguales. Una petición exitosa que tardó 50 milisegundos tiene la misma probabilidad de ser capturada que una que falló después de 30 segundos. Desde la perspectiva de entender qué está roto, esto no tiene ningún sentido.
Conviene también distinguir dos variantes del muestreo que generan mucha confusión. El head-based sampling toma la decisión de capturar o descartar una traza en el momento en que empieza, antes de conocer su resultado: es eficiente pero ciego, porque no puede saber si esa traza acabará siendo un error o una traza lenta. El tail-based sampling retrasa esa decisión hasta haber visto todos los spans de la traza, lo que permite aplicar criterios mucho más precisos, aunque a costa de mayor complejidad operativa, porque hay que mantener las trazas en memoria hasta que estén completas. La telemetría adaptativa suele apoyarse en tail-based sampling o en combinaciones de ambos.
Cómo funciona la telemetría adaptativa
La telemetría adaptativa invierte la lógica: en lugar de decidir de antemano qué porcentaje de datos vas a capturar, defines reglas que determinan cuándo algo merece atención completa. Estas reglas evalúan características de las transacciones en tiempo real: duración, códigos de error, endpoints específicos, atributos de usuario, patrones de comportamiento.
Un sistema adaptativo típico mantiene una tasa de muestreo baja para el tráfico normal. Quizás capturas el 0,1% de las peticiones que completan exitosamente en menos de 100 milisegundos. Pero cuando una transacción cruza un umbral de latencia, devuelve un error 500, o pertenece a un flujo crítico como el proceso de pago, el sistema aumenta automáticamente la tasa de captura para ese tipo de tráfico.
La parte interesante es que estas decisiones se toman en el momento de la instrumentación, no después. Cuando tu aplicación está a punto de generar un span, el agente o SDK evalúa si esa transacción específica cumple criterios que justifiquen capturarla con detalle completo. Esto significa que puedes ser extremadamente selectivo sin perder información crítica.
Dynatrace implementó este enfoque a escala con su tecnología PurePath y su mecanismo Adaptive Traffic Management (ATM). A diferencia de la mayoría de sistemas que gestionan el muestreo de forma aislada por agente, Dynatrace gestiona el volumen pico de trazas a nivel de entorno completo: las aplicaciones de bajo volumen ceden su cuota no utilizada a las de alto volumen que la necesitan. Dentro de esa cuota, el sistema prioriza capturar la mayoría de las peticiones únicas y raras, y una proporción menor de las peticiones de alta frecuencia. El muestreo, por tanto, no es aleatorio sino orientado a maximizar la diversidad informativa de los datos capturados.
OpenTelemetry ha madurado significativamente en este área. En octubre de 2025, el proyecto publicó hitos importantes en su especificación de sampling, con el nuevo ProbabilitySampler reemplazando gradualmente al antiguo TraceIdRatioBased, y con soporte formal para muestreo probabilístico consistente en sistemas distribuidos: todos los servicios de una cadena pueden tomar decisiones coordinadas aunque tengan cuotas diferentes. Esta mejora, desarrollada con contribuciones de ingenieros de Dynatrace, Honeycomb, Microsoft, Cisco y Datadog, resuelve uno de los problemas históricos más irritantes del muestreo distribuido.
Honeycomb ha construido parte de su propuesta de valor precisamente alrededor de esta idea. Su herramienta Refinery actúa como proxy de tail-based sampling: las trazas se acumulan en memoria hasta estar completas, y solo entonces se aplican las reglas de decisión. El resultado es que puedes garantizar que el 100% de los errores y trazas lentas se conservan, mientras reduces drásticamente el volumen del tráfico normal.
Qué puedes hacer con menos datos pero mejor señal
La primera ventaja es obvia: reduces costes. Pero no de forma proporcional al volumen que eliminas, porque estás eliminando principalmente ruido. Si pasas de capturar 100 millones de spans al día a 5 millones, pero esos 5 millones incluyen todos los errores, todas las transacciones lentas y todos los flujos críticos, tu capacidad de diagnosticar problemas no disminuye. De hecho, probablemente mejora.
Hay algo más sutil que ocurre cuando reduces el volumen de forma inteligente: tus herramientas de análisis funcionan mejor. Las consultas son más rápidas. Los dashboards cargan en segundos en lugar de minutos. Puedes mantener ventanas de retención más largas con el mismo presupuesto. Y lo más importante: cuando buscas un problema específico, no tienes que filtrar entre millones de transacciones normales para encontrar las pocas que fallaron.
Esto cambia la experiencia de investigar incidentes. En lugar de empezar con una consulta amplia que devuelve demasiados resultados y luego ir refinando, empiezas con un conjunto de datos que ya está orientado hacia lo interesante. Es la diferencia entre buscar una aguja en un pajar y buscar una aguja en una caja de agujas sospechosas.
Dónde se complica la implementación
La telemetría adaptativa suena perfecta en teoría, pero implementarla bien requiere resolver varios problemas no triviales. El primero es definir qué significa «interesante». Parece sencillo: errores, latencias altas, endpoints críticos. Pero en la práctica, cada sistema tiene sus propias definiciones de qué constituye un comportamiento anómalo.
Un endpoint que normalmente responde en 50 milisegundos y de repente tarda 200 es claramente interesante. Pero otro que habitualmente tarda 2 segundos y ahora tarda 2,5 quizás no lo sea. Necesitas umbrales específicos por servicio, por endpoint, incluso por tipo de usuario. Y esos umbrales tienen que ajustarse automáticamente conforme tu sistema evoluciona, porque lo que era lento hace tres meses puede ser normal hoy.
El segundo problema es la coordinación en sistemas distribuidos. Una transacción que atraviesa cinco servicios puede parecer normal en cuatro de ellos pero anómala en el quinto. Si cada servicio toma decisiones de muestreo de forma independiente, puedes terminar con trazas incompletas: tienes el span del servicio donde ocurrió el problema, pero no tienes contexto de los servicios anteriores que llevaron a esa situación.
La solución habitual es propagar decisiones de muestreo a través de headers HTTP o metadatos de mensajería. Si el primer servicio en una cadena decide que una transacción merece captura completa, todos los servicios de la cadena respetan esa decisión. OpenTelemetry define mecanismos para esto, y la especificación de 2025 los ha formalizado de forma más robusta, aunque sigue siendo necesario que toda la instrumentación esté coordinada y actualizada.
Hay un tercer problema más filosófico: a veces no sabes que algo es interesante hasta después de que ocurre. Un patrón de comportamiento puede parecer normal en el momento pero resultar ser el precursor de un problema mayor que se manifiesta minutos u horas después. La telemetría adaptativa basada en reglas no puede capturar esto porque las decisiones se toman en tiempo real. El tail-based sampling mitiga parcialmente este problema al retardar la decisión, pero no lo elimina del todo.
Cuándo tiene sentido y cuándo no
La telemetría adaptativa aporta más valor en sistemas con alto volumen de transacciones donde la mayoría del tráfico es predecible y exitoso. Si tienes millones de peticiones al día pero solo cientos de errores, tiene todo el sentido del mundo capturar todos los errores con detalle completo y solo una muestra pequeña del tráfico normal.
También es especialmente útil cuando tus costes de observabilidad están creciendo más rápido que tu capacidad de extraer valor de los datos. Si estás pagando por volumen de datos ingeridos o almacenados, y una parte significativa de esos datos nunca se consulta ni aporta información útil, la telemetría adaptativa puede reducir drásticamente esos costes sin sacrificar capacidad de diagnóstico.
Pero no es una solución universal. En sistemas pequeños o medianos donde el volumen total de telemetría es manejable, la complejidad adicional de implementar muestreo adaptativo puede no justificarse. A veces es más simple y más efectivo capturar todo y pagar el coste.
Tampoco funciona bien cuando necesitas análisis estadísticos precisos sobre todo tu tráfico. Si estás calculando percentiles de latencia o analizando distribuciones de comportamiento de usuario, necesitas muestras representativas de todo el espectro, no solo de los extremos. En esos casos, el muestreo tradicional con tasas conocidas te da garantías estadísticas que el muestreo adaptativo puro no puede ofrecer.
La evolución hacia sistemas más inteligentes
Lo interesante es que la telemetría adaptativa está evolucionando hacia enfoques aún más sofisticados. Algunas plataformas están empezando a usar aprendizaje automático para identificar patrones anómalos que no se pueden capturar con reglas simples. En lugar de definir umbrales fijos de latencia o tasas de error, el sistema aprende qué es normal para cada endpoint en diferentes momentos del día y bajo diferentes condiciones de carga.
Proyectos como Cilium están explorando cómo aplicar estos conceptos a nivel de red, capturando selectivamente flujos de tráfico basándose en políticas y comportamiento observado. Falco hace algo similar para eventos de seguridad, filtrando el ruido de syscalls normales para enfocarse en comportamientos sospechosos. La idea central es la misma: ser selectivo de forma inteligente en lugar de capturar todo o muestrear ciegamente.
Lo que realmente importa
Al final, la telemetría adaptativa no es tanto una tecnología específica como un cambio de mentalidad. Durante años asumimos que más datos siempre era mejor, que el problema era solo de almacenamiento y procesamiento. Pero la realidad es que demasiados datos pueden ser tan problemáticos como muy pocos, porque dificultan encontrar la señal en medio del ruido.
La pregunta correcta no es «¿cuántos datos puedo permitirme capturar?» sino «¿qué datos necesito para entender y resolver problemas cuando ocurren?». Y la respuesta a esa pregunta casi nunca es «una muestra aleatoria del 1% de todo». Es más probable que sea «todo lo que falla, todo lo que es anormalmente lento, todo lo que afecta a flujos críticos, y una muestra pequeña del resto para mantener contexto».
Implementar esto requiere pensar cuidadosamente sobre qué define «interesante» en tu sistema específico, coordinar decisiones de muestreo a través de servicios distribuidos, y aceptar que nunca tendrás visibilidad perfecta de todo. Pero a cambio obtienes algo más valioso: visibilidad completa de lo que realmente importa, a una fracción del coste de intentar capturarlo todo.
Para seguir aprendiendo
OpenTelemetry — Conceptos de Sampling Documentación oficial que explica los diferentes tipos de samplers, cuándo usar head-based vs tail-based, y los nuevos samplers basados en probabilidad consistente introducidos en la especificación de 2025.
Dynatrace — Adaptive Traffic Management Explicación técnica del mecanismo ATM de Dynatrace: cómo gestiona el volumen de trazas a nivel de entorno, cómo prioriza peticiones únicas frente a las frecuentes, y cómo interactúa con las licencias DPS.
«Observability Engineering» — Charity Majors, Liz Fong-Jones y George Miranda (O’Reilly) Capítulos sobre estrategias de sampling y cómo diseñar instrumentación que capture lo que importa sin ahogar tus sistemas en datos.
«Distributed Tracing in Practice» — Austin Parker et al. (O’Reilly) Sección dedicada a estrategias de muestreo en sistemas distribuidos y los desafíos de mantener coherencia en decisiones de captura a través de múltiples servicios.
