
Cuando se habla de observabilidad, la definición que más circula por ahí es la de «la capacidad de entender el estado interno de un sistema a partir de sus salidas externas». Es una definición correcta, pero abstracta. Lo que la hace concreta son las señales que un sistema genera: los datos que, bien recogidos y correlacionados, permiten responder a preguntas arbitrarias sobre lo que está ocurriendo sin necesidad de haber anticipado esas preguntas de antemano.
Históricamente, esas señales se han agrupado en tres pilares: logs, métricas y trazas. La denominación «tres pilares» sigue siendo útil como marco conceptual, aunque en 2026 vale la pena matizarla: OpenTelemetry, que se ha convertido en el estándar de facto para la instrumentación, ya reconoce oficialmente una cuarta señal — los perfiles de rendimiento continuo (profiling) — que entró en alpha pública en 2026. No cambia la esencia del artículo, pero conviene saberlo si trabajas con OTel.
Esta entrega se centra en los logs: qué son, por qué importan más de lo que parece, y cómo implementarlos bien.
Qué son los logs y por qué siguen siendo el pilar más consultado
Un log es un registro de un evento discreto que ha ocurrido en un sistema: algo pasó, en un momento concreto, en un lugar concreto, con un contexto concreto. Son la narrativa textual de lo que ha sucedido. Históricamente fueron la herramienta principal de los administradores de sistemas para depurar problemas reactivamente, y esa función no ha desaparecido — simplemente se ha ampliado.
En sistemas modernos, los logs son también fuente de datos para auditoría, seguridad, análisis del comportamiento de usuarios e inteligencia operativa. Pero su papel más crítico en arquitecturas de microservicios es este: cuando una transacción de negocio atraviesa decenas de servicios independientes, cada uno ejecutándose en su propio contenedor, el rastro de la ejecución se fragmenta. Los logs, si están bien estructurados y correlacionados, permiten reconstruir esa secuencia de eventos, identificar dónde ocurrió el problema y por qué.
Esa última palabra — «por qué» — es la que diferencia a los logs de las otras señales. Las métricas te dicen que algo fue mal. Las trazas te muestran dónde fue mal. Los logs te explican qué ocurrió exactamente en ese momento.
Los retos reales de gestionar logs a escala
El problema principal no es técnico sino de volumen. En infraestructuras de cierto tamaño, los logs se generan a una velocidad que puede superar fácilmente los cientos de gigabytes diarios. Eso crea tres problemas simultáneos: coste de almacenamiento, rendimiento de búsqueda y coste de indexación. A esto se añade la variabilidad de formatos: si cada servicio escribe sus logs de una manera diferente, el análisis automatizado y la correlación entre servicios se vuelven muy difíciles.
Estos dos problemas — volumen y falta de estandarización — son exactamente los que llevan a los equipos a invertir tiempo en configurar bien los logs desde el principio, porque arreglarlo después es mucho más costoso.
Buenas prácticas para implementar logs correctamente
Logging estructurado
El cambio más importante que puede hacer un equipo que todavía escribe logs en texto libre es pasarse al logging estructurado: JSON o pares clave-valor en lugar de cadenas de texto sin estructura. La diferencia es enorme desde el punto de vista operativo: un log estructurado es indexable, consultable y procesable por cualquier herramienta de gestión de logs. Un log en texto libre obliga a parsear con expresiones regulares frágiles cada vez que quieres extraer información de él.
Los campos mínimos que debería tener cualquier entrada de log son: timestamp, level, service_name, host, message y trace_id o correlation_id. Ese último campo es el que permite correlacionar los logs de una misma solicitud a través de múltiples servicios.
Contextualización y correlación
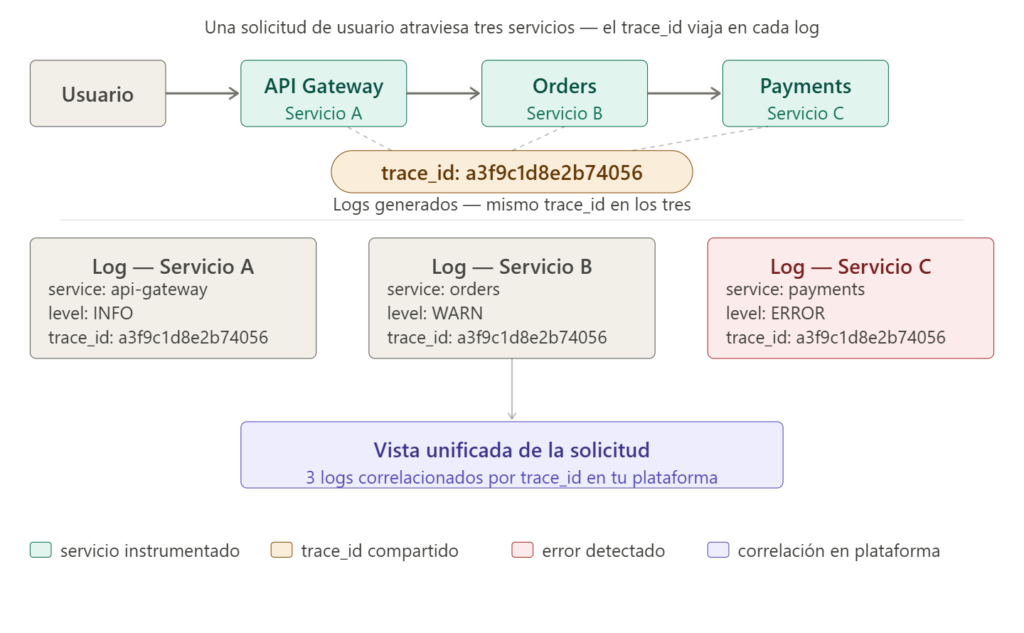
En un sistema distribuido, una solicitud de usuario puede pasar por cinco servicios distintos antes de producir una respuesta. Si cada servicio escribe sus logs de forma independiente sin incluir un identificador común, reconstruir lo que ocurrió en esa solicitud concreta es prácticamente imposible.
La solución es incluir un trace_id o request_id en cada entrada de log generada dentro del contexto de esa solicitud, y propagarlo a través de todos los servicios involucrados. Este identificador es el que permite unificar los logs dispersos en una vista coherente. Y es también el que conecta los logs con las trazas distribuidas: si usas OpenTelemetry, el trace_id del log y el de la traza son el mismo, lo que permite saltar directamente del log al trace completo en tu plataforma de observabilidad.
Niveles de log con criterio
Los niveles de log (DEBUG, INFO, WARN, ERROR, FATAL) son útiles solo si se usan de forma consistente y con criterio. El error más común es abusar del nivel ERROR para eventos que en realidad son WARNING, o usar INFO para todo y convertirlo en ruido. Una buena regla práctica: ERROR significa que algo ha fallado y requiere atención; WARN significa que algo está en un estado degradado pero el sistema sigue funcionando; INFO es para eventos significativos del ciclo de vida de la aplicación; DEBUG es para información de diagnóstico que solo deberías activar temporalmente en entornos de desarrollo o durante una investigación.
Definir estos criterios explícitamente en la documentación interna del equipo, y revisarlos en las revisiones de código, evita que los logs se conviertan en ruido después de unos meses de operación.
Nunca logs con datos sensibles
Los logs no deben contener información personal identificable, credenciales, tokens, datos financieros ni ningún otro dato sensible. Esto parece obvio pero es un error más común de lo que debería, especialmente en entornos donde los logs de depuración incluyen el payload completo de las peticiones. La solución es implementar filtros o procesadores en la capa de ingesta — OpenPipeline en Dynatrace, procesadores del Collector de OpenTelemetry, o reglas de Logstash — que eliminen o enmascaren estos campos antes de que los logs lleguen al almacenamiento.
Estandarización entre equipos
Si cada equipo decide su propio esquema de logs, la capacidad de correlación entre servicios se resiente. Definir una convención común para los nombres de campos, los valores de los niveles de log y los identificadores de correlación, y documentarla en un lugar accesible, es una inversión que se amortiza rápidamente en cualquier organización con varios equipos.
Herramientas de gestión de logs: dónde van a parar
Un sistema de logs sin una plataforma centralizada de gestión es prácticamente inútil a escala. Las opciones más habituales en 2026 son el stack ELK (Elasticsearch, Logstash o Fluentd, Kibana), Grafana Loki, Splunk, y las soluciones nativas de los proveedores cloud como CloudWatch Logs (AWS) o Azure Monitor Logs.
Loki merece una mención especial porque su modelo de indexación es diferente al de Elasticsearch: en lugar de indexar el contenido completo de los logs, solo indexa las etiquetas (labels), lo que lo hace mucho más económico a escala. La contrapartida es que las búsquedas de texto libre son más lentas. Para la mayoría de casos de uso donde los logs están bien etiquetados y se consultan principalmente por servicio, nivel o trace_id, Loki es una opción muy competitiva.
Si usas OpenTelemetry como capa de instrumentación, el Collector de OTel puede recibir logs de tus aplicaciones y exportarlos simultáneamente a múltiples backends, lo que te da flexibilidad para cambiar de plataforma en el futuro sin tocar el código de instrumentación.
El lugar de los logs en la triada de observabilidad
Los tres tipos de señal no son alternativas entre sí: son complementarias. Las métricas te dan una visión agregada y cuantitativa del sistema — cuántas peticiones por segundo, qué porcentaje de error, cuánta CPU. Las trazas te muestran el camino completo de una petición a través de tus servicios, con la duración de cada operación. Los logs te dan el detalle granular de qué ocurrió exactamente en cada punto de ese camino.
En la práctica, el flujo de diagnóstico habitual es: una métrica se degrada o dispara una alerta, la traza muestra dónde está el problema, y los logs revelan el mensaje de error exacto, la condición de carrera o el valor inesperado que lo causó. Cada señal responde a una pregunta diferente, y las tres juntas son lo que permite diagnosticar problemas complejos en sistemas distribuidos de forma sistemática en lugar de intuitiva.
La clave para que esto funcione no es solo tener las tres señales, sino que estén correlacionadas: que el trace_id del log sea el mismo que el del trace, que los labels de las métricas identifiquen el mismo servicio que los logs. OpenTelemetry resuelve este problema de raíz al proporcionar un modelo de datos y un protocolo de transporte (OTLP) compartido para las tres señales, más los perfiles que se van incorporando.
Resumiendo
Los logs han pasado de ser una herramienta de depuración reactiva a un componente estratégico de la observabilidad moderna. Su valor no está en el volumen que generan sino en la calidad de la información que contienen: si están bien estructurados, correctamente etiquetados, libres de datos sensibles y correlacionados con el resto de señales, son la fuente más rica de contexto que tienes sobre el comportamiento de tus sistemas.
Implementarlos bien desde el principio — con logging estructurado, trace_id propagado y niveles semánticos consistentes — es una de las inversiones de mayor retorno que puede hacer un equipo de operaciones. Arreglarlo después, cuando ya tienes terabytes de logs en formato texto libre sin correlación, es una historia mucho más larga.
