
:: Artículo actualizado en abril de 2025 ::
Configurar alertas en Dynatrace es uno de los primeros retos con los que se encuentra cualquier persona que empieza a trabajar con la plataforma. No porque sea complicado técnicamente, sino porque Dynatrace ofrece varios mecanismos distintos para conseguir lo mismo, y no siempre queda claro cuál usar en cada situación.
Este artículo explica los componentes principales del sistema de alertas, cuándo usar cada uno, y cómo encajan entre sí. También incluye una nota sobre la dirección hacia la que está evolucionando la plataforma, porque Dynatrace está en un proceso de transición que conviene conocer desde el principio para no construir sobre algo que ya está en camino de quedar obsoleto.
El punto de partida: Davis AI detecta, tú decides qué hacer con ello
Antes de entrar en configuraciones, es importante entender el modelo mental de Dynatrace. La plataforma no se limita a comprobar si una métrica supera un umbral y disparar una alerta. Dynatrace tiene una capa de inteligencia artificial llamada Davis AI que monitoriza continuamente el comportamiento de todos los componentes instrumentados, aprende qué es normal para cada uno de ellos, y detecta anomalías de forma automática.
Cuando Davis AI detecta un problema, crea un Problem: un objeto que agrupa todos los eventos relacionados con el mismo incidente, identifica la causa raíz más probable y muestra el impacto sobre usuarios y servicios. Un Problem puede estar formado por un solo evento o por decenas de eventos correlacionados que Davis AI ha decidido que comparten la misma causa subyacente. Esto es lo que evita la tormenta de alertas que suele producirse en herramientas más tradicionales cuando cae un componente compartido.
La configuración de alertas en Dynatrace consiste esencialmente en dos cosas: definir qué condiciones deben generar un evento (detección), y definir qué debe ocurrir cuando ese evento existe (notificación y enrutamiento).
Metric Events: definir tus propias condiciones de detección
Davis AI detecta muchas cosas de forma automática y sin configuración. Pero hay casos de negocio específicos que la plataforma no puede adivinar por sí sola: que tu tasa de error supere el 2% en el endpoint de pagos, que el tiempo de respuesta de un servicio concreto supere 500 ms, o que el uso de CPU de un servidor específico esté por encima del 85% durante más de cinco minutos. Para esos casos existen los Metric Events.
Los Metric Events se configuran en Settings > Anomaly Detection > Metric events y existen en dos variantes con comportamientos bien distintos:
Metric Key Events
Evalúan las mediciones en bruto de una única métrica, tal como llegan a la plataforma, sin posibilidad de transformaciones ni agregaciones. Solo admiten umbrales estáticos. Son la opción más sencilla y la más adecuada cuando quieres monitorizar una métrica individual con una condición fija y directa.
Un caso típico: alertar si el porcentaje de CPU de cualquier host supera el 90%. La ventaja de este tipo es que puede cubrir miles de dimensiones (todos los hosts del entorno) en una sola configuración.
Metric Selector Events
Evalúan una consulta de métrica compleja definida mediante metric selector, con acceso a datos históricos y soporte para operaciones aritméticas entre métricas. Admiten tres estrategias de monitorización:
- Umbral estático: el valor más simple. Alerta si la métrica supera o baja de un valor fijo.
- Umbral auto-adaptativo: Davis AI calcula automáticamente el umbral en base al comportamiento histórico de la métrica y lo ajusta dinámicamente. Útil cuando el comportamiento normal varía mucho entre horas punta y valle.
- Línea de base estacional: Davis AI crea una banda de confianza teniendo en cuenta patrones repetitivos (día de la semana, hora del día). Adecuado para métricas con patrones cíclicos bien definidos.
Un caso típico para Metric Selector: alertar si la tasa de error de un servicio calculada como el porcentaje de peticiones fallidas sobre el total supera un umbral, agregando datos de las últimas dos horas para evitar falsos positivos por picos momentáneos.
La sliding window: el parámetro que más confunde al principio
Tanto en Metric Key como en Metric Selector existe el concepto de sliding window (ventana deslizante), que es uno de los parámetros que más confunden a quienes empiezan. La sliding window define el periodo de tiempo durante el cual se evalúan las muestras. Por defecto, Dynatrace requiere que 3 de cada 5 muestras de un minuto violen el umbral para abrir un evento. Esto evita que un pico puntual de un segundo dispare una alerta.
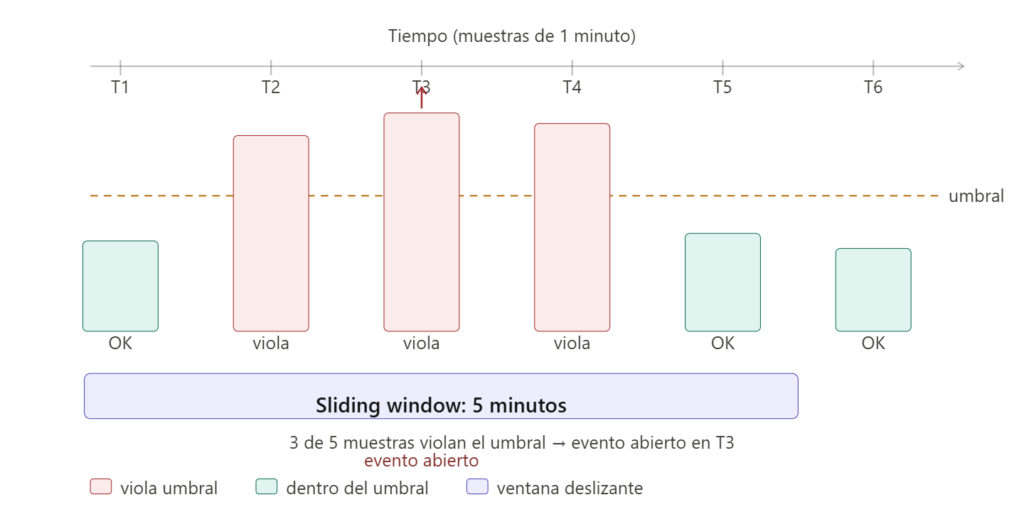
El evento permanece abierto hasta que el número de muestras que vuelven a estar dentro del umbral supera el umbral de «dealert» dentro de esa misma ventana. Un consejo práctico de la comunidad: si quieres detección rápida (por ejemplo, 3 de 5 muestras) pero no quieres que el problema se cierre y abra constantemente durante el día, necesitas un número de muestras de dealert suficientemente alto (al menos violating_samples + 1). Una configuración como 3/5 violando y 3/5 para cerrar puede producir que el problema abra y cierre varias veces seguidas si el sistema oscila alrededor del umbral.
Alerting Profiles: filtrar y enrutar problemas
Los Alerting Profiles (Settings > Alerting > Problem alerting profiles) no detectan nada por sí solos. Su función es filtrar qué problemas deben generar una notificación y a quién debe llegar esa notificación.
Cada entorno tiene un perfil por defecto que notifica todos los problemas. Lo habitual en entornos reales es crear perfiles específicos por equipo, por Management Zone, o por tipo de problema. Un perfil puede configurarse para notificar solo si el problema lleva abierto más de X minutos (útil para filtrar problemas que Davis AI resuelve automáticamente en segundos), solo para problemas de una severidad determinada, o solo para entidades con ciertas etiquetas.
Los filtros dentro de un Alerting Profile funcionan con lógica AND para las condiciones de una regla, y lógica OR entre reglas distintas del mismo perfil. El matching de etiquetas es exacto: si defines la etiqueta equipo:backend, solo coincidirá con entidades que tengan exactamente esa clave y ese valor.
Problem Notifications: los canales de salida
Las Problem Notifications (Settings > Integration > Problem notifications) son los canales por los que Dynatrace envía el aviso al exterior: correo electrónico, Slack, PagerDuty, Opsgenie, ServiceNow, o un webhook genérico para cualquier otro sistema.
Cada notificación se asocia a un Alerting Profile, de forma que el perfil determina qué problemas generan la notificación y el canal determina dónde llega. La integración con ServiceNow, por ejemplo, permite crear tickets automáticamente con los detalles del problema, mapear la severidad de Dynatrace a la prioridad de ServiceNow, y asignar el ticket a un grupo de resolución específico.
Una nota importante: hacia dónde va esto
Dynatrace está en un proceso de transición que conviene conocer antes de invertir mucho tiempo en configurar el sistema clásico de Alerting Profiles + Problem Notifications. La plataforma está migrando ese modelo hacia Workflows, que ofrecen mucho más control sobre qué ocurre cuando se detecta un problema: enrutamiento dinámico según el propietario de la entidad afectada, lógica condicional, integración con múltiples canales en una misma automatización, y acciones de remediación automática.
Según la propia comunidad de Dynatrace y las comunicaciones oficiales, los Alerting Profiles y Problem Notifications no van a desaparecer de inmediato y no hay fecha de obsolescencia anunciada. Pero la recomendación de Dynatrace es empezar a adoptar Workflows para nuevas configuraciones, especialmente en entornos SaaS con acceso a las capacidades más recientes de la plataforma. Si estás empezando desde cero en un entorno nuevo, vale la pena explorar los Workflows desde el principio.
Davis Anomaly Detectors: el puente entre Metric Events y Workflows
Existe un tercer mecanismo de detección que el artículo original no mencionaba y que es relevante conocer: los Davis Anomaly Detectors, accesibles desde la app Anomaly Detection en la plataforma más reciente.
Funcionan de forma similar a los Metric Selector Events, pero están diseñados para integrarse directamente con el sistema de Workflows y admiten consultas DQL sobre datos almacenados en Grail, lo que los hace mucho más potentes: pueden alertar sobre logs, spans, Business Events y cualquier otra fuente de datos disponible en Grail, no solo sobre métricas.
La regla de uso que circula en la comunidad es sencilla: si la métrica tiene una frecuencia de actualización alta (un dato por minuto o más), usa un Davis Anomaly Detector. Si la métrica es lenta o escasa (un dato por hora o menos), considera el Site Reliability Guardian combinado con un Workflow.
Cómo encaja todo: el flujo completo
Para que quede claro cómo se relacionan estos componentes, el flujo de una alerta en Dynatrace funciona así:
Primero, Davis AI o un Metric Event detecta una anomalía y crea un evento. Si el evento es suficientemente significativo, Davis AI abre un Problem agrupando todos los eventos relacionados. El Alerting Profile evalúa ese Problem y decide si cumple los criterios para generar una notificación. Si los cumple, la Problem Notification lo envía al canal configurado (correo, ServiceNow, Slack…). Opcionalmente, un Workflow puede dispararse también sobre ese Problem para ejecutar acciones adicionales: enrutar según el propietario, abrir un ticket, ejecutar un script de remediación.
Configuración paso a paso para empezar
Paso 1: crear un Alerting Profile específico
Ve a Settings > Alerting > Problem alerting profiles y crea un perfil nuevo. Define el alcance usando Management Zones si tienes el entorno organizado por zonas, o usando etiquetas para filtrar entidades específicas. Configura las reglas de severidad para que solo notifique los tipos de problema que realmente requieren atención del equipo. Añade un retardo de apertura si quieres evitar que problemas que Davis AI resuelve en menos de dos minutos generen una notificación.
Paso 2: configurar Metric Events para tus KPIs críticos
Ve a Settings > Anomaly Detection > Metric events y crea un nuevo evento. Para métricas simples con umbral fijo, usa tipo Metric Key. Para métricas que necesiten agregación, histórico o umbrales adaptativos, usa tipo Metric Selector. Define siempre un título descriptivo y un mensaje de evento que incluya los placeholders {alert_condition} y {dims} para que quien reciba la alerta sepa inmediatamente qué ha pasado y sobre qué entidad. Configura la sliding window en la sección de propiedades avanzadas: el valor por defecto de 3/5 es un buen punto de partida, pero ajústalo según la criticidad y la velocidad de reacción que necesitas.
Paso 3: configurar el canal de notificación
Ve a Settings > Integration > Problem notifications, añade una notificación del tipo que corresponda (correo, ServiceNow, webhook…) y asóciala al Alerting Profile creado en el paso 1. Para ServiceNow, configura las credenciales de la instancia, el mapeo de severidades, y el grupo de asignación. Para correo electrónico, personaliza el asunto y el cuerpo del mensaje para que incluya la información relevante del problema.
Paso 4: validar antes de poner en producción
Usa la función de previsualización disponible en la configuración de Metric Events para ver cómo se habría comportado la configuración sobre datos históricos reales. Esto permite detectar si el umbral elegido habría generado demasiadas alertas o si habría pasado por alto incidentes conocidos. Ajusta la sliding window y el umbral hasta que el comportamiento de la previsualización sea coherente con lo que esperas ver en producción.
Buenas prácticas para no acabar ahogado en alertas
No alertes sobre todo desde el principio. Empieza con los dos o tres KPIs más críticos de tu servicio y añade más gradualmente. Una configuración de alertas que genera decenas de notificaciones al día se ignora igual que ninguna.
Usa la sliding window siempre. Nunca configures un Metric Event sin revisar las propiedades avanzadas. El valor por defecto (3 de 5 muestras) ya es razonable, pero entender qué significa te permite adaptarlo a cada caso.
Confía en Davis AI para la correlación. No intentes replicar con Metric Events lo que Davis AI ya hace automáticamente. Si un servicio falla porque la base de datos que usa está caída, Davis AI lo correlacionará y creará un solo Problem con la causa raíz correcta. Crear un Metric Event para cada síntoma por separado solo añade ruido.
Usa Management Zones y etiquetas para el enrutamiento. Es mucho más mantenible enrutar alertas basándose en etiquetas de entidad que crear un Alerting Profile diferente para cada equipo con listas de entidades hardcodeadas.
Documenta los umbrales y el razonamiento detrás de ellos. Un umbral de 85% de CPU que nadie sabe por qué es 85% y no 90% es un problema futuro garantizado. Deja constancia de por qué se eligió ese valor y cuándo fue la última vez que se revisó.
Resumiendo
El sistema de alertas de Dynatrace es más potente que el de la mayoría de herramientas de monitorización, pero tiene más piezas que aprender a encajar. La clave para no perderse al principio es entender el orden de responsabilidades: Davis AI detecta y correlaciona, los Metric Events añaden condiciones de negocio específicas, los Alerting Profiles filtran y enrutan, y las Problem Notifications o los Workflows entregan el aviso al canal correcto.
Si estás empezando con Dynatrace, dedica tiempo a entender cómo funciona Davis AI antes de lanzarte a crear Metric Events para todo. Muchos de los problemas que quieres detectar ya los está detectando la plataforma de forma automática. Configurar bien el enrutamiento y las notificaciones sobre lo que Davis AI ya ve suele ser el paso que más valor aporta con menos esfuerzo.
Para profundizar, la documentación oficial de Dynatrace sobre Metric Events y sobre Alerting Profiles es completa y está bien mantenida. La comunidad de Dynatrace tiene también hilos muy útiles sobre casos concretos de configuración de sliding windows y sobre la transición hacia Workflows.
