Imagínate que tienes un montón de sensores repartidos por toda tu infraestructura: servidores, contenedores, bases de datos, aplicaciones. Hasta ahora, para recoger métricas, logs y trazas, confiabas en Grafana Agent, una pieza ligera que hacía de colector. Pero llega Grafana Alloy, que promete hacer lo mismo y más, con un enfoque distinto. ¿Qué significa esto para tu stack? ¿De verdad es un cambio para mejor o solo otro nombre para lo mismo? Vamos a desentrañarlo.
Cuando Grafana Agent se queda corto: la necesidad de un nuevo enfoque
Grafana Agent nació para ser un colector ligero, capaz de enviar datos a Loki, Tempo o Mimir. En teoría, un todo en uno para la observabilidad moderna. Pero en la práctica, cuando tu infraestructura crece o se vuelve más heterogénea, empiezas a notar ciertas limitaciones. La configuración puede volverse compleja, la gestión de actualizaciones se complica, y la flexibilidad para integrar distintos protocolos o fuentes de datos no siempre es la ideal.
Además, Agent está pensado para desplegarse en cada nodo o servicio, lo que significa gestionar un montón de instancias con configuraciones similares pero dispersas. Si has trabajado en un entorno con cientos o miles de nodos, sabes que esto puede convertirse en un dolor de cabeza. La falta de un modelo nativo para escalar horizontalmente o distribuir la carga de scraping entre instancias hace que pierdas control a medida que creces.
Y hay algo más importante: Grafana Agent llegó a End-of-Life el 1 de noviembre de 2025. Ya no recibe actualizaciones de seguridad, correcciones de bugs ni soporte del fabricante. Si todavía lo tienes en producción, la migración no es opcional.
Lo mismo aplica a Promtail, el agente de recolección de logs para Loki que mucha gente usa sin pasar por Agent: también está deprecado y con EOL previsto para principios de 2026. Alloy lo reemplaza igualmente.
Grafana Alloy: qué es y qué aporta realmente
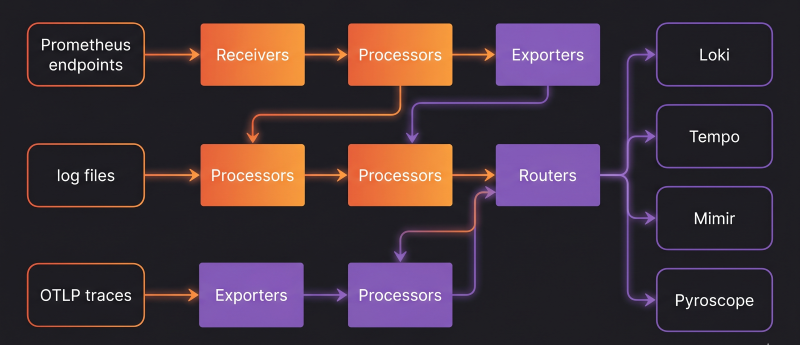
Grafana Alloy es una distribución de OpenTelemetry Collector, 100% compatible con OTLP, con pipelines nativos para métricas, logs, trazas y perfiles. No es una capa encima de Agent ni un orquestador de agentes: es directamente el colector, instalado donde antes vivía Agent (o Promtail).
Lo que lo hace diferente no es solo que unifique señales en un solo binario, sino cómo está construido por dentro. Alloy funciona mediante componentes, piezas independientes que se conectan entre sí para formar pipelines configurables. Cada componente hace una cosa: scrapeear métricas, transformar logs, filtrar trazas, reenviar a un destino. Tú decides cómo conectarlos en ficheros .alloy, el formato de configuración propio de Alloy.
Esta arquitectura modular tiene una ventaja práctica enorme: puedes ver exactamente qué está pasando en cada paso del pipeline. Alloy incluye una interfaz web embebida que muestra el grafo de componentes y su estado en tiempo real, lo que convierte el debugging de configuraciones en algo mucho menos frustrante que editar YAML a ciegas.
Clustering: escalar sin duplicar trabajo
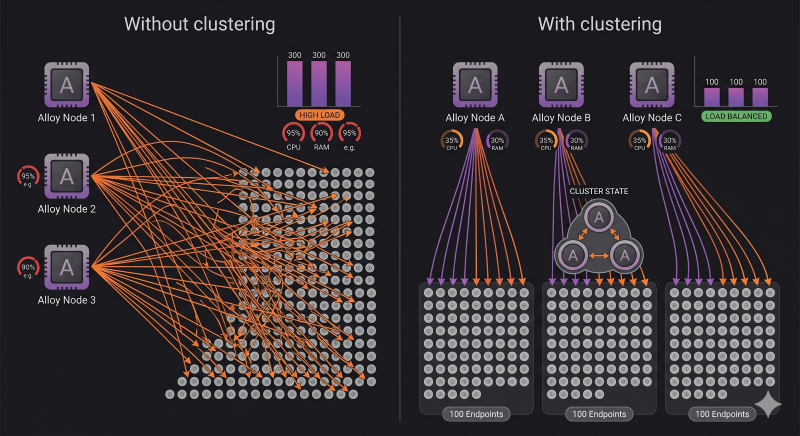
Una de las diferencias más relevantes para entornos grandes es el clustering nativo. Con Agent, si querías alta disponibilidad o distribuir la carga de scraping entre varias instancias, tenías que resolver eso tú mismo fuera de la herramienta.
Con Alloy, varias instancias pueden formar un clúster y repartirse el trabajo automáticamente. El funcionamiento práctico es sencillo de entender: imagina que tienes 300 endpoints de Prometheus para scrapear y tres instancias de Alloy. El clúster se reparte el trabajo y cada instancia coge aproximadamente 100. Si una instancia cae o se añade una nueva, el reparto se reajusta solo en cuestión de segundos, sin intervención manual ni configuración adicional. Grafana Labs usa este mecanismo internamente para scrapear casi 20 millones de series métricas activas en su propia infraestructura de Grafana Cloud.
Otras capacidades que merece la pena conocer
Soporte de profiling: Alloy va más allá de las tres señales clásicas (métricas, logs, trazas) e incorpora soporte para profiling continuo a través de Pyroscope. Si estás empezando a explorar el análisis de rendimiento a nivel de código, ya tienes el colector preparado.
Integración con Beyla: Alloy puede incorporar Grafana Beyla, la herramienta de auto-instrumentación basada en eBPF de Grafana Labs. Esto permite obtener trazas y métricas de aplicaciones sin tocar su código, especialmente útil en entornos donde no controlas el despliegue de la aplicación.
GitOps-friendly: Alloy puede cargar su configuración desde repositorios Git, buckets S3 u otros endpoints HTTP. Para equipos que gestionan infraestructura como código, esto simplifica enormemente el ciclo de vida de la configuración del colector.
Seguridad integrada: Alloy se conecta nativamente a HashiCorp Vault para recuperar secretos, evitando tener credenciales en texto plano en los ficheros de configuración.
¿Cómo funciona Alloy en tu stack de observabilidad?
Si antes tenías Grafana Agent en cada nodo enviando datos a Loki, Tempo o Mimir, Alloy ocupa exactamente ese lugar. La diferencia está en la forma de configurarlo y en las capacidades adicionales que trae.
La migración desde Agent no es complicada en la mayoría de los casos: Alloy incluye una herramienta de conversión (alloy convert) que traduce configuraciones existentes de Agent (tanto Static como Flow) al formato .alloy. No es magia, pero reduce significativamente el trabajo manual en entornos con configuraciones estándar.
Para entornos que llegaban desde Promtail, el proceso es similar: existe una guía de migración específica en la documentación oficial.
¿Cuándo tiene sentido cambiar y cuándo no?
Si tu infraestructura es pequeña y tu stack de observabilidad no es complejo, es probable que la urgencia sea menor… aunque no inexistente, dado el EOL de Agent. La cuestión no es tanto si migrar, sino cuándo y con qué calma.
Si tienes problemas con la gestión de múltiples agentes, necesitas distribuir la carga de scraping entre instancias, o quieres unificar métricas, logs, trazas y perfiles sin multiplicar componentes, Alloy es la respuesta directa.
Lo que sí hay que tener claro es que la transición requiere entender el modelo de componentes y pipelines. No es un cambio de nombre con otro fichero de configuración: es una forma diferente de pensar cómo fluyen los datos de telemetría por tu infraestructura. Vale la pena invertir algo de tiempo en leer la documentación y hacer pruebas antes de migrar producción.
¿Qué no soluciona Alloy?
Alloy mejora la recopilación y gestión de datos, pero no es una solución para todos los problemas de observabilidad. No elimina la necesidad de diseñar buenos SLOs, ni de decidir qué métricas o logs son realmente relevantes. Tampoco sustituye a las herramientas de análisis o visualización: las complementa.
Al ser una plataforma más expresiva, puede requerir más tiempo de configuración inicial que simplemente pegar un fichero YAML de Agent. Si tu equipo no está familiarizado con el modelo de componentes, la curva de aprendizaje existe, aunque es razonable.
En resumen: Alloy no es opcional, es el siguiente paso
Grafana Alloy no es solo una mejora sobre Agent: es su sustituto oficial, con Agent ya fuera de soporte. Recoge la experiencia acumulada y la lleva hacia un modelo más flexible, escalable y alineado con los estándares abiertos de la industria. Si tu stack todavía depende de Agent o Promtail, la pregunta no es si migrar, sino cuándo.
Para seguir aprendiendo
- Documentación oficial de Grafana Alloy: punto de partida para entender la arquitectura, los componentes disponibles y cómo configurarlos.
- Repositorio de Grafana Alloy en GitHub: código fuente, issues y ejemplos de la comunidad.
- Grafana Alloy al año: novedades y hoja de ruta: post oficial de Grafana Labs con cifras de adopción y las mejoras del primer año.
- OpenTelemetry Specification: para entender cómo Alloy se integra con el estándar abierto de observabilidad.
- Observability Engineering, Charity Majors, Liz Fong-Jones y George Miranda (O’Reilly): referencia sólida sobre los fundamentos y buenas prácticas de observabilidad, independientemente de la herramienta.
