Prometheus se ha consolidado como la piedra angular en la monitorización de sistemas y aplicaciones en entornos nativos de la nube. Su modelo de datos basado en series temporales, junto con su ecosistema abierto y extensible, lo convierten en la opción predilecta para ingenieros de fiabilidad de sitios (SRE) y arquitectos de observabilidad. Sin embargo, el proyecto no es estático: las versiones más recientes, y especialmente la consolidación de Prometheus 3.0 — la primera versión mayor en siete años, publicada en noviembre de 2024 — han introducido cambios técnicos de calado que impactan directamente en la operación, la escalabilidad y la usabilidad en entornos de producción.
A fecha de este artículo, Prometheus ya va por la versión 3.5.0 LTS (Long Term Support), con múltiples versiones menores publicadas desde el 3.0 que siguen refinando las funcionalidades que analizamos aquí.
Este artículo analiza esos cambios clave, aportando una perspectiva crítica y práctica para profesionales sénior. No se trata de un simple listado de novedades, sino de un análisis sobre qué implican estos cambios, cuándo merece la pena adoptarlos y cuáles son sus limitaciones actuales.
Una interfaz completamente nueva
Quizá el cambio más visible para el administrador en su día a día sea la interfaz web completamente reescrita que trae Prometheus 3.0. La antigua interfaz, construida sobre Bootstrap y acumulando años de decisiones de diseño superpuestas, ha sido sustituida por una reescritura completa basada en Mantine, un framework moderno de componentes React.
El resultado es una interfaz más limpia, con menos ruido visual, y que incorpora funcionalidades que antes requerían herramientas externas:
- Explorador de métricas y etiquetas: permite buscar todas las métricas disponibles junto con sus metadatos, profundizar en los nombres y valores de etiquetas de una métrica concreta, y ver la cardinalidad de cada combinación. Esto facilita enormemente la construcción de consultas sin tener que recurrir a la documentación o a ensayo y error.
- Vista de árbol estilo PromLens: cualquier consulta PromQL puede visualizarse como un árbol de subexpresiones, mostrando cuántas series evalúa cada nodo y qué datos de etiquetas contiene. Esta funcionalidad proviene de PromLens, el constructor de consultas que fue donado al proyecto Prometheus.
- Pestaña «Explain»: ofrece información contextual y de comportamiento sobre las métricas seleccionadas, algo que antes simplemente no existía en la interfaz nativa.
Para quienes prefieran la interfaz anterior, es posible volver a ella temporalmente mediante el flag --enable-feature=old-ui. Pero la recomendación del equipo de desarrollo es adoptar la nueva cuanto antes y reportar cualquier problema en GitHub.
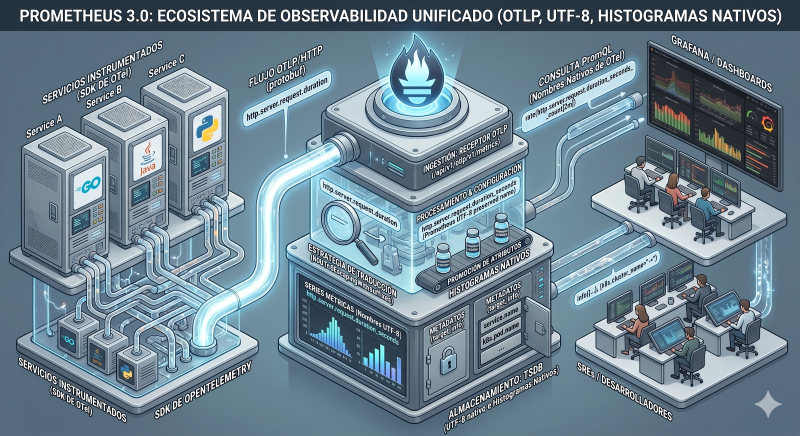
Arquitectura y escalabilidad: histogramas nativos frente a la cardinalidad
Uno de los focos principales de evolución ha sido la optimización del rendimiento del almacenamiento local. Se han introducido mejoras sustanciales en el motor TSDB (Time Series Database) que gestionan de forma mucho más eficiente la cardinalidad masiva, un problema histórico en despliegues de gran tamaño.
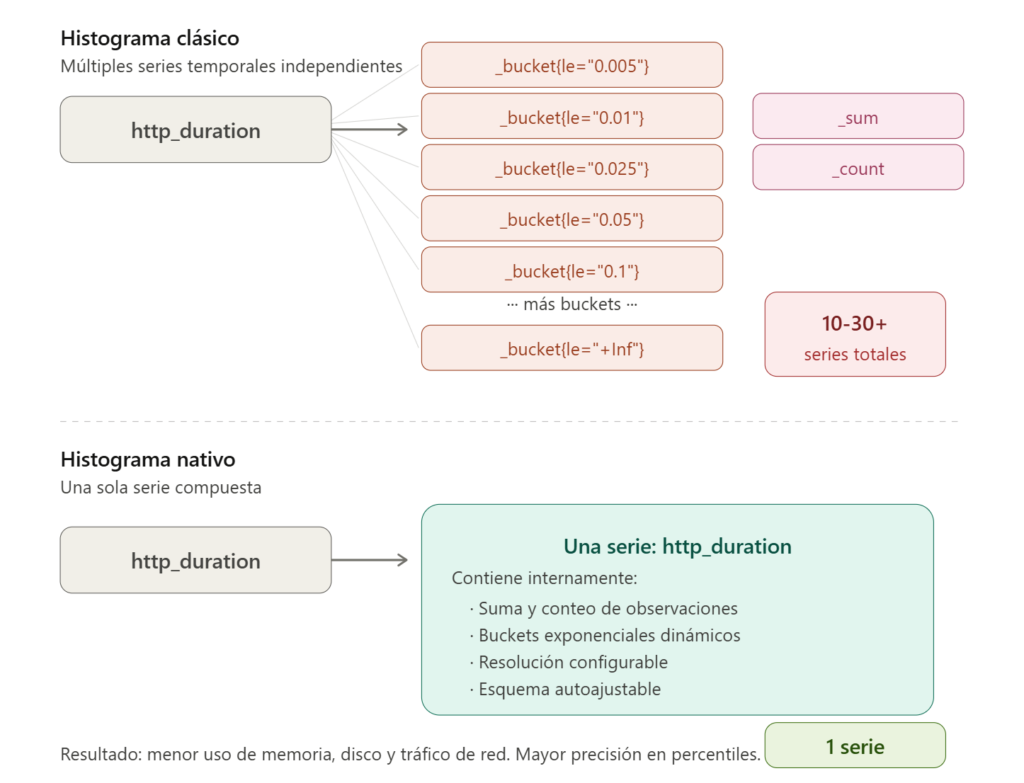
El cambio técnico más ambicioso es la introducción de los Histogramas Nativos (Native Histograms). A diferencia de los histogramas clásicos, que requerían múltiples series temporales independientes — una por cada nivel o bucket, más las series de suma y conteo — los histogramas nativos comprimen toda la distribución en una sola serie compuesta de alta resolución.
Impacto técnico: Esto reduce drásticamente el uso de memoria y disco, y permite calcular percentiles con una precisión mucho mayor. Los límites de los buckets se crean dinámicamente siguiendo un esquema exponencial, cubriendo todo el rango de números en coma flotante sin necesidad de definir límites manualmente durante la instrumentación. Además, con la versión 3.0 los histogramas nativos soportan la ingesta fuera de orden (out-of-order ingestion), lo que resuelve escenarios habituales de desconexiones temporales o huecos en la recogida de métricas.
Nota importante sobre madurez: A pesar de su potencial, los histogramas nativos siguen siendo una funcionalidad experimental. No están habilitados por defecto y se activan mediante --enable-feature=native-histograms. Algunos aspectos, como el formato de texto y ciertos operadores y funciones de acceso en PromQL, siguen en fase de diseño activo. Además, el soporte en las librerías de instrumentación es todavía limitado: actualmente solo las librerías oficiales de Go y Java soportan histogramas nativos, y requieren exposición mediante el formato protobuf. El soporte en formato de texto está en desarrollo como parte de OpenMetrics 2.0.
Para quienes ya tienen histogramas clásicos desplegados, existe una opción de transición: los NHCB (Native Histograms with Custom Bucket boundaries), que permiten a Prometheus ingerir histogramas clásicos como nativos durante la migración, con un manejo idéntico en PromQL.
Estas mejoras no eliminan la necesidad de arquitecturas horizontales en grandes despliegues. Herramientas como Thanos, Cortex o Mimir siguen siendo imprescindibles para la federación de datos y la retención a largo plazo. La mejora en la TSDB facilita la operación diaria, pero la complejidad de la monitorización distribuida sigue requiriendo una capa de agregación robusta.
Interoperabilidad total: OTLP, UTF-8 y el retorno de OpenMetrics
Prometheus como receptor nativo de OpenTelemetry
El cambio de paradigma más relevante en cuanto a interoperabilidad es el soporte nativo para OpenTelemetry (OTel). Prometheus ya no es solo un sistema de extracción (pull); ahora puede recibir métricas directamente a través del protocolo OTLP en el endpoint /api/v1/otlp/v1/metrics. Esto lo posiciona como una pieza central en los flujos de datos modernos, permitiendo que las aplicaciones envíen datos sin necesidad de exportadores o agentes intermedios.
El fin de las restricciones en el etiquetado (UTF-8)
Una de las novedades más esperadas por la comunidad internacional ha sido el soporte completo para UTF-8 en los nombres de métricas y etiquetas, habilitado por defecto desde la versión 3.0. Hasta hace poco, estábamos limitados a caracteres ASCII básicos. Con este cambio, Prometheus permite una integración mucho más natural con otros sistemas de observabilidad — especialmente con OpenTelemetry, donde la conversión automática de puntos a guiones bajos en nombres de métricas era una fuente constante de confusión — y facilita la migración desde herramientas que no tenían estas restricciones, eliminando la necesidad de aplicar transformaciones complejas en la ingesta de datos.
Las consultas PromQL pueden escribirse con la nueva sintaxis de comillas para acceder a métricas con caracteres UTF-8, o bien especificando manualmente la etiqueta __name__.
OpenMetrics: archivado y reintegrado
Un dato relevante que completa este panorama de interoperabilidad: OpenMetrics, el proyecto que nació como un intento de convertir el formato de exposición de Prometheus en un estándar independiente bajo la CNCF, fue oficialmente archivado en julio de 2024 y reintegrado bajo la gobernanza de Prometheus. La iniciativa, que incluso llegó a explorar la vía de un estándar IETF, no consiguió tracción suficiente como proyecto independiente.
La buena noticia es que esto simplifica el ecosistema: un solo formato de referencia, un solo proyecto que lo mantiene. Ya se ha establecido un grupo de trabajo para OpenMetrics 2.0, ahora directamente bajo Prometheus, que integrará los aprendizajes acumulados.
Remote Write 2.0: eficiencia real en el envío de datos
El nuevo protocolo Remote Write 2.0 representa una mejora tangible para cualquier despliegue que envíe métricas a sistemas externos. La clave técnica es el uso de tablas de símbolos (string interning): en lugar de repetir los mismos nombres de métricas y etiquetas en cada lote, el protocolo los referencia mediante índices, reduciendo drásticamente el tamaño de los mensajes.
Los números hablan por sí solos. Según datos publicados por Grafana Labs tras migrar toda su infraestructura interna de monitorización a Remote Write v2, la reducción del tráfico de salida (egress) se sitúa entre el 50% y el 60% respecto al formato anterior, con un incremento de CPU y memoria de apenas un 5-10%. En las pruebas presentadas en KubeCon NA 2024, las cifras fueron aún más agresivas: un 60% de reducción en mensajes transmitidos, un 90% menos de asignación de memoria y un 70% de reducción en uso de CPU.
Esto es vital en entornos de nube donde el tráfico de salida y la computación se facturan al milímetro. Remote Write 2.0 también incorpora soporte nativo para metadatos, exemplars, marcas de tiempo de creación (created timestamps) e histogramas nativos, lo que lo convierte en un protocolo mucho más completo que su predecesor.
Es importante señalar que Remote Write 2.0 sigue marcado como experimental en Prometheus, aunque ya cuenta con adopción amplia tanto en Prometheus como en backends receptores como Mimir. Prometheus gestiona automáticamente el fallback a la versión 1.0 si el receptor no soporta la versión 2.0.
Gestión de reglas y alertas: validación y recarga automática
La gestión de reglas de registro y de alerta se ha profesionalizado. Las últimas versiones incorporan mecanismos de recarga dinámica más fiables y una validación de sintaxis mucho más rigurosa, lo que minimiza los errores en los flujos de despliegue continuo (CI/CD).
Una novedad concreta de Prometheus 3.0 es la recarga automática del fichero de configuración a intervalos especificados. Esto va más allá de la recarga mediante señal SIGHUP o endpoint HTTP que ya existía: el servidor puede ahora detectar y aplicar cambios de configuración de forma periódica y autónoma, lo que simplifica los flujos de trabajo en entornos orquestados.
La integración con Alertmanager se ha refinado para soportar escenarios complejos de enrutamiento. No obstante, desde un punto de vista de ingeniería, estas mejoras no sustituyen la necesidad de adoptar buenas prácticas, como las pruebas unitarias para reglas de PromQL. Un error común es confiar en que la flexibilidad de las nuevas versiones resuelve problemas de diseño; si una consulta tiene una cardinalidad explosiva, la alerta seguirá siendo un cuello de botella.
Observabilidad y FinOps: controlando el coste de la métrica
Para el administrador moderno, la monitorización ya no es solo una cuestión de disponibilidad, sino de eficiencia de costes. Las versiones recientes de Prometheus incluyen mejores herramientas para identificar qué métricas están consumiendo más recursos — las llamadas «métricas calientes» o de alta cardinalidad — a través del explorador de métricas integrado en la nueva interfaz.
Combinando las mejoras del motor TSDB, los histogramas nativos y Remote Write 2.0, los equipos de ingeniería tienen por primera vez las herramientas para atacar el coste de la monitorización desde múltiples frentes simultáneamente. La reducción real dependerá de cada despliegue, pero los datos publicados por la comunidad y por proveedores como Grafana Labs apuntan a reducciones significativas tanto en consumo de almacenamiento local como en tráfico de red hacia backends remotos.
Seguridad: TLS nativo y la imagen distroless
Históricamente, Prometheus delegaba la seguridad a capas externas. Las versiones recientes han integrado soporte nativo para TLS y autenticación básica en su interfaz y API.
Una novedad adicional en materia de seguridad es la disponibilidad de una imagen Docker distroless como alternativa a la imagen basada en BusyBox. La variante distroless proporciona una superficie de ataque mínima, utiliza UID/GID 65532 (nonroot) en lugar de nobody, y elimina la declaración VOLUME. Ambas variantes están disponibles con sufijos de etiqueta (-busybox y -distroless), manteniendo la imagen BusyBox como predeterminada por compatibilidad.
Aunque estos avances son bienvenidos, para entornos multi-inquilino o con requisitos de auditoría estrictos, la recomendación experta sigue siendo el uso de un proxy inverso o un API Gateway especializado. La seguridad nativa es funcional, pero carece de la granularidad de un sistema de control de acceso basado en roles (RBAC) completo.
Ruta de migración: lo que hay que saber antes de actualizar
Para quienes estén considerando la migración a Prometheus 3.x, hay un dato operativo crítico: se recomienda encarecidamente actualizar primero a la versión 2.55 antes de saltar a la 3.0. El rollback desde 3.0 solo es posible a 2.55, no a versiones anteriores. Saltarse este paso puede dejarte sin marcha atrás en caso de problemas.
Prometheus 3.0 incluye varios cambios que rompen la compatibilidad (breaking changes), aunque la mayoría son limpieza de flags experimentales obsoletos. Los cambios afectan a:
- Feature flags eliminados: varios flags experimentales han sido eliminados y su funcionalidad activada por defecto. Las referencias a estos flags deben eliminarse de la configuración.
- Selectores de rango: ahora son abiertos por la izquierda y cerrados por la derecha (left-open, right-closed), lo que evita casos raros donde se incluían más puntos de los esperados.
- Modo Agent: promovido a estable con su propio argumento de línea de comandos (
--agent) en lugar de un feature flag. - Scrape protocols: cambios en la negociación del protocolo de extracción, especialmente relevantes para quienes usan protobuf.
La buena noticia, según los propios mantenedores, es que la mayoría de los usuarios deberían poder ejecutar Prometheus 3.0 sin cambios en su configuración. Pero en producción, verificar siempre es mejor que asumir.
Resumiendo
Las últimas versiones de Prometheus representan un salto cualitativo hacia la madurez técnica. La adopción de estándares como OpenTelemetry, la optimización radical del almacenamiento con histogramas nativos, la reescritura completa de la interfaz, la eficiencia de Remote Write 2.0 y la reintegración de OpenMetrics bajo su gobernanza demuestran que el proyecto sabe adaptarse a las necesidades de la observabilidad moderna sin perder su identidad.
Sin embargo, la herramienta mantiene su esencia: es un sistema optimizado para métricas. Para una observabilidad de 360 grados, sigue siendo imperativo complementarlo con soluciones como Tempo (trazas) y Loki (registros), ambas integradas en el ecosistema de Grafana Labs. La decisión de actualizar debe ser estratégica: no solo por tener la última versión, sino por habilitar capacidades que reduzcan la deuda técnica y los costes operativos.
Para saber más
He seleccionado estas fuentes por su rigor técnico y actualidad:
- Anuncio oficial de Prometheus 3.0: El desglose detallado de todas las nuevas funcionalidades de la versión mayor.
- Documentación: Histogramas Nativos: La especificación técnica completa del nuevo tipo de dato.
- Buenas prácticas: Histogramas y Summaries: Guía oficial actualizada sobre cuándo y cómo usar cada tipo de histograma.
- Prometheus: Up & Running, 2ª Edición (O’Reilly): La edición más reciente (noviembre 2024), que cubre Prometheus 3.0 y OpenTelemetry.
- Configuración del receptor OTLP: Referencia técnica para habilitar la ingesta directa de datos de OpenTelemetry.
- La nueva interfaz de Prometheus 3.0 (PromLabs): Artículo detallado de Julius Volz sobre el diseño y funcionalidades de la nueva UI.
- Remote Write v2: reducción de costes de egress (Grafana Labs): Datos reales de la migración interna de Grafana Labs.
