Son las seis de la tarde de un jueves y la tasa de error de tu servicio de checkout empieza a subir. Despacio, sin alarmas, pero subiendo. Revisas el historial de despliegues y está limpio: nadie ha tocado producción en las últimas seis horas. Las métricas generales están dentro de lo normal, los dashboards en verde, las latencias aceptables. Y sin embargo, un goteo de peticiones a la cadena API Gateway → Checkout → Validación de tarjetas → Antifraude externo está fallando de forma intermitente.
Cuarenta minutos después, alguien de otro equipo cae en la cuenta: esa misma tarde activaron un feature flag que enruta el 15% del tráfico por un nuevo camino de validación de tarjetas. El flag no es un despliegue. No aparece en tu timeline de releases, no genera un evento en tu stack de observabilidad, no deja rastro en tus trazas. Existe en el código y en un panel de gestión, pero para tu monitorización es invisible. Ese 15% degradado se diluye en el 85% sano, y tú llevas casi una hora persiguiendo un fantasma que cualquier correlación automática habría señalado en el primer minuto.
Esta desconexión entre lo que activas progresivamente y lo que observas no es un detalle menor. Es la diferencia entre detectar un problema en minutos o en horas, y entre saber si un rollback fue efectivo o quedarte con la duda de si la mejora que ves es real o casualidad estadística.
Feature flags: del interruptor oculto a la señal observable
Los feature flags llevan años siendo una práctica estándar para desacoplar el despliegue del código de la activación de funcionalidades. Permiten hacer rollouts progresivos, probar en producción con usuarios reales y revertir cambios sin redesplegar. Pero tradicionalmente han vivido en un silo: una biblioteca en tu aplicación, quizá un servicio de gestión externo, y poco más.
El salto conceptual que propone OpenFeature es tratar los feature flags como ciudadanos de primera clase en tu arquitectura de observabilidad. No como un detalle de implementación que vive en el código, sino como contexto operativo que debe fluir por tus trazas, métricas y logs de la misma forma que fluye el identificador de una petición o el nombre de un servicio.
OpenFeature es un estándar abierto bajo licencia Apache 2.0 y proyecto en incubación de la Cloud Native Computing Foundation desde noviembre de 2023 (fue aceptado por la CNCF en junio de 2022). Define una API neutral para trabajar con feature flags. La idea es simple: tu código no debería acoplarse a un proveedor específico. Usas una interfaz común y, por debajo, puedes cambiar de proveedor sin tocar tu aplicación. Piensa en ello como lo que OpenTelemetry hizo por la instrumentación de observabilidad, pero para feature flags. La analogía no es casual: parte de la misma gente y de la misma filosofía de evitar el lock-in a nivel de código.
Pero la parte realmente interesante no es la abstracción en sí. Es que, al estandarizar cómo se consultan y evalúan los flags, se abre la puerta a integrarlos profundamente con el resto del stack de observabilidad. Y ahí es donde el movimiento de Dynatrace en torno a DevCycle muestra hacia dónde va esto.
Dynatrace y DevCycle: el flag como contexto de primera clase
Conviene poner las cosas en orden, porque el panorama cambió hace poco. Dynatrace fue una de las empresas que inició y lideró el estándar OpenFeature en 2022. Y en enero de 2026 dio el siguiente paso lógico: adquirió DevCycle, una plataforma de gestión de feature flags construida de forma nativa sobre OpenFeature (la primera que se definió así). Es decir, ya no hablamos de «dos productos que se integran», sino de una pieza de feature management que entra directamente en la plataforma de observabilidad.
DevCycle, por estar construido sobre OpenFeature, no encierra a nadie: puedes usar Dynatrace con DevCycle o con cualquier sistema de flags compatible con OpenFeature. Esto preserva la apertura del estándar y evita el lock-in, que es justo lo que daría mala espina si la jugada fuera «compro un proveedor y te obligo a usarlo».
La promesa de fondo no es «ver los flags en un dashboard». Es que cada evaluación de un feature flag se convierta en contexto que viaja con la traza distribuida de esa petición. Imagina un servicio de recomendaciones que usa un nuevo algoritmo de ranking activado por un flag solo para usuarios premium en Europa. Cuando el servicio procesa una petición, evalúa el flag. Con la integración, esa evaluación no se queda en un booleano interno: queda registrada y correlacionada con la traza, enriqueciéndola con qué flag se evaluó, qué valor devolvió y bajo qué reglas.
Así, cuando analizas una traza lenta, no solo ves que el servicio de recomendaciones tardó 800 milisegundos. Ves que tardó 800 milisegundos cuando el flag del nuevo algoritmo estaba activo. Puedes filtrar trazas por estado de flags, comparar latencias entre usuarios con el flag activo y sin él, y correlacionar errores con cambios de configuración de flags sin cruzar manualmente datos de dos sistemas distintos.
Cómo funciona de verdad: hooks, spans y PurePath
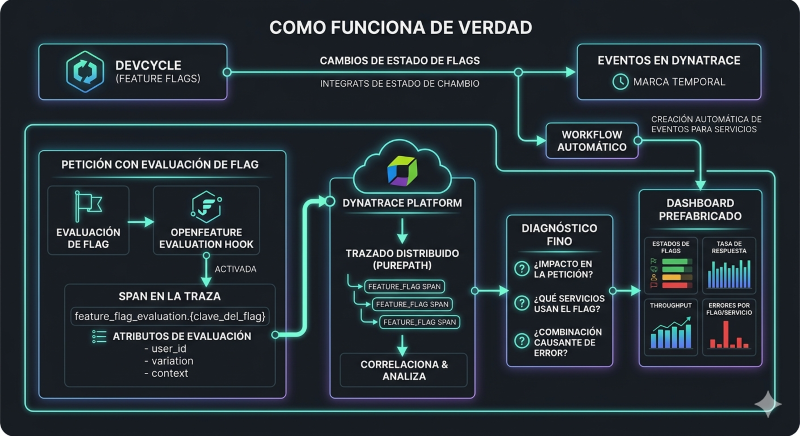
Aquí merece la pena bajar al detalle, porque la magia tiene fontanería. La integración se monta en dos partes.
La primera conecta DevCycle con Dynatrace para que los cambios de estado de un flag lleguen como eventos. Como los flags pueden cambiar independientemente de los despliegues, normalmente no aparecen en tus herramientas de observabilidad; este canal asegura que cada modificación quede registrada en Dynatrace con su marca temporal.
La segunda es la que importa para el diagnóstico fino: enviar las evaluaciones de flags como parte de las trazas. Esto se consigue mediante los Evaluation Hooks de OpenFeature, que los SDK de DevCycle ya soportan. Cuando los activas, cada evaluación genera un span (con el patrón feature_flag_evaluation.{clave_del_flag}) que lleva como atributos los detalles de esa evaluación. Por debajo, Dynatrace usa su tecnología de trazado distribuido, PurePath, para ver todos los flags que se evaluaron en una petición concreta y qué valores devolvieron. Eso permite responder con datos a preguntas que antes eran conjeturas: ¿qué impacto tuvo el valor de este flag en la petición?, ¿qué servicios están usando este flag?, ¿fue una combinación concreta de flags la que provocó el comportamiento raro?
Como guinda práctica, la integración incluye un workflow y un dashboard prefabricados que se importan en Dynatrace. El workflow crea automáticamente eventos de cambio de flag para los servicios que emiten spans, sin tener que mapear servicios a flags a mano; el dashboard muestra la evolución de los estados de los flags junto con tasa de respuesta, throughput y errores por flag y por servicio. No es imprescindible, pero ahorra la parte tediosa de montar la visualización desde cero.
Más allá de las trazas: métricas dimensionadas por flags
La cosa no se queda en las trazas. Las métricas que se recopilan —latencia, tasa de error, throughput— pueden dimensionarse con el estado de los flags relevantes. Eso significa dashboards que muestran el rendimiento de tu aplicación segmentado por variante de flag, sin instrumentar a mano cada métrica.
En la práctica, esto cambia cómo haces rollouts progresivos. Activas un flag para el 5% de los usuarios, esperas unos minutos y consultas directamente si ese 5% está viendo más errores, más latencia o cualquier anomalía. No necesitas montar experimentos A/B manuales ni exportar datos de tu sistema de flags para cruzarlos con tus métricas. El contexto ya está ahí, pegado a la señal.
De la observación a la acción: cerrar el bucle
El argumento de fondo de la adquisición es pasar «de la observabilidad a la acción»: que las decisiones de rollout se informen directamente de lo que observas. Con los Workflows de Dynatrace puedes construir automatizaciones que reaccionen a señales —por ejemplo, disparar un aviso o un evento cuando un flag recién activado correlaciona con un pico de errores—.
Conviene ser honesto con el alcance: que la plataforma «desactive sola» un flag problemático y vuelva a una variante segura sin intervención es la dirección hacia la que apunta todo esto, pero no es un botón llave-en-mano que venga configurado de fábrica. Hoy tienes los ingredientes —eventos de cambio de flag, evaluaciones en las trazas, workflows— y con ellos puedes acercarte bastante a ese bucle cerrado. Pero el último tramo, el de la remediación automática, sigue siendo trabajo de orquestación tuyo, y conviene meterlo con cabeza: un rollback automático mal calibrado puede hacer tanto daño como el problema que intenta resolver.
OpenFeature como puente, no como destino
Lo interesante de OpenFeature no es solo lo que habilita con Dynatrace. Es que, al ser un estándar abierto, el contexto de los flags puede fluir por todo tu stack independientemente de las herramientas que uses. Existe un conjunto de hooks de OpenTelemetry para OpenFeature que añaden la información de cada evaluación a trazas, métricas y logs siguiendo las semantic conventions de OTel (con atributos como feature_flag.key, feature_flag.provider_name o feature_flag.variant). Y como lo que emiten es telemetría OTel estándar, esa señal puede acabar en cualquier backend compatible: Jaeger para las trazas, Prometheus para las métricas, o el destino que prefieras.
Esto es especialmente relevante en organizaciones grandes donde cada equipo usa herramientas distintas. Si todos adoptan OpenFeature como interfaz común, el contexto de flags viaja entre servicios instrumentados con OpenTelemetry, métricas en Prometheus y trazas en Dynatrace sin que cada equipo reimplemente la integración.
Ahora bien, el estándar todavía tiene aristas. La semantic convention de feature flags en OpenTelemetry sigue en estado de desarrollo, y de hecho los span events —la forma original de registrar evaluaciones dentro de una traza— están en proceso de deprecación en favor de los log events. Si montas tu instrumentación hoy, merece la pena tenerlo en cuenta para no apoyarte en algo que va a cambiar. Como siempre, el estándar te da portabilidad, a veces a costa de renunciar a capacidades muy específicas de un proveedor y de convivir con partes que aún se están asentando.
Cuándo tiene sentido este enfoque (y cuándo no)
Integrar feature flags con observabilidad a este nivel no sale gratis. Exige adoptar un estándar como OpenFeature, elegir proveedores que lo soporten bien y repensar cómo instrumentas tus aplicaciones. Merece la pena cuando tu estrategia de despliegue depende de rollouts progresivos, cuando trabajas con arquitecturas distribuidas donde el contexto se pierde con facilidad, o cuando necesitas responder rápido a problemas en producción sin redesplegar.
Si tu equipo hace despliegues tradicionales —todo o nada, sin fases— y los flags son solo un mecanismo ocasional para ocultar trabajo en progreso, probablemente no necesitas esta complejidad. Una biblioteca sencilla de flags y buenos dashboards manuales pueden bastar.
Pero si despliegas varias veces al día, tienes múltiples servicios interdependientes y un problema en producción puede afectar a millones de usuarios, correlacionar automáticamente el comportamiento del sistema con qué funcionalidades están activas deja de ser un lujo y se convierte en una necesidad operativa.
El coste de la visibilidad
Hay compensaciones. Cada evaluación de flag que genere telemetría añade volumen de datos. En sistemas de alto tráfico, esto puede traducirse en costes significativos si no afinas qué evaluar y con qué detalle. No todas las evaluaciones necesitan generar un span completo: algunas pueden ser simples métricas agregadas, otras pueden muestrearse.
También está el riesgo de sobrecargar el contexto. Si cada petición carga el estado de docenas de flags, las trazas se vuelven ruidosas y difíciles de leer. La clave es ser selectivo: instrumenta los flags que de verdad importan para entender el comportamiento del sistema, no todos los que existen en el código.
Entrega progresiva observable: el siguiente paso
La entrega progresiva no es solo activar un flag y esperar. Es un proceso iterativo de desplegar, observar, ajustar y repetir. Tradicionalmente, cada paso requería herramientas distintas —un sistema de flags para controlar el rollout, otro de observabilidad para ver qué pasa— y mucho trabajo manual para correlacionar ambos.
Lo que propone una integración como la de Dynatrace y DevCycle es cerrar ese bucle: que la observabilidad sea consciente de qué estás desplegando progresivamente y que las decisiones de rollout se informen de lo que observas, sin fricción entre sistemas. Eso cambia la velocidad a la que puedes iterar de forma segura. Puedes hacer rollouts más agresivos porque tienes visibilidad inmediata de su impacto, experimentar en producción con más confianza y revertir con precisión quirúrgica.
La observabilidad siempre ha tratado de entender qué está pasando en tu sistema. Pero si no puedes ver qué funcionalidades están activas, para quién y cómo afectan al comportamiento, estás observando solo la mitad de la historia. OpenFeature y las integraciones que habilita no resuelven todos los problemas de la entrega progresiva, pero sí dan un paso importante para que los feature flags dejen de ser un detalle invisible y pasen a ser parte del contexto que necesitas para decidir con datos. Y el flag que tocó otro equipo un jueves a las seis de la tarde deja de ser un fantasma.
Para seguir aprendiendo
- OpenFeature Specification — Especificación oficial del estándar, mantenida por la CNCF. Define la API de evaluación, el contexto de evaluación, los hooks y los eventos.
- Semantic conventions for feature flags (OpenTelemetry) — Convenciones de OTel para registrar evaluaciones de flags en trazas, logs y métricas. Útil para entender qué atributos se capturan y por qué los span events están migrando a log events.
- DevCycle — Guía de integración con Dynatrace — Documentación oficial paso a paso: Evaluation Hooks, tokens, y el workflow y dashboard prefabricados para importar en Dynatrace.
- Dynatrace — OpenFeature y la estandarización de feature flags — Explicación de Dynatrace sobre cómo correlaciona evaluaciones de flags con trazas distribuidas usando PurePath.
- Dynatrace adquiere DevCycle — Anuncio oficial de la adquisición (enero de 2026) y el encaje con el estándar OpenFeature.
- Observability Engineering, de Charity Majors, Liz Fong-Jones y George Miranda (O’Reilly Media) — Capítulos sobre contexto distribuido y cómo instrumentar aplicaciones para que el contexto operativo fluya por trazas y métricas.
