
Es lunes por la mañana. Todavía no has terminado tu primer café cuando el canal de incidentes de Slack empieza a echar humo. Tu servicio de pagos, el corazón de la empresa, está respondiendo con una latencia inasumible. El equipo de negocio ya ha enviado tres correos preguntando por qué la tasa de conversión está cayendo en picado.
Abres tu tablero de control. Tienes métricas que muestran que la CPU está al 80%, trazas distribuidas que indican que las peticiones tardan el doble de lo normal, y logs que, para variar, no dicen nada útil más allá de un genérico «timeout». Tienes los síntomas, tienes la ubicación del dolor, pero te falta el diagnóstico preciso. Nadie en la sala puede responder a la pregunta que realmente importa en ese momento de crisis: ¿qué función exacta, qué línea de código específica, está consumiendo esos ciclos de CPU?
¿Es una validación de tarjetas mal implementada? ¿Un algoritmo de cifrado que no escala? ¿O quizás algo tan mundano como una serialización JSON que nadie esperaba que fuera tan costosa? Durante años, la respuesta a esa pregunta ha vivido en un exilio tecnológico, fuera del ecosistema de observabilidad estándar. Pero el panorama ha cambiado radicalmente: OpenTelemetry Profiles ha entrado oficialmente en alpha pública, consolidándose como el cuarto pilar de la observabilidad.
El eslabón perdido: ¿Qué es exactamente un «Profile»?
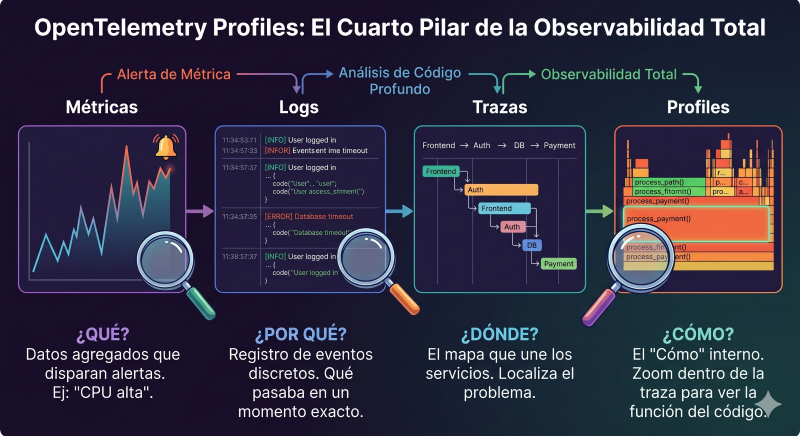
Antes de sumergirnos en la revolución de OpenTelemetry, debemos entender qué es este nuevo pilar. Si las métricas, los logs y las trazas son la «santísima trinidad» de la observación, el profiling es la capacidad de realizar una autopsia en tiempo real del comportamiento interno de un programa.
Imagina que tu aplicación es un restaurante.
- Las Métricas te dicen cuántos clientes hay y cuánto tardan en salir (el «qué»).
- Las Trazas te muestran el camino de un pedido desde que entra hasta que se sirve (el «dónde»).
- El Profiling es como poner un cronómetro en la mano de cada cocinero para saber exactamente cuántos segundos pasan picando cebolla, cuánto tiempo esperan a que hierva el agua y cuánto tardan en emplatar.
Técnicamente, un profile es una colección de datos estadísticos sobre la ejecución de un programa. La mayoría de los profilers modernos funcionan mediante muestreo (sampling). En lugar de registrar cada microsegundo de ejecución (lo cual destruiría el rendimiento), el profiler «asoma la cabeza» miles de veces por segundo y pregunta: «¿Qué función se está ejecutando en este hilo ahora mismo?». Al final del proceso, agrega todas esas respuestas para decirte, por ejemplo, que el 70% del tiempo de CPU se gastó en la función hash_password().
El resultado visual más común de este proceso es el Flame Graph (gráfico de llamas). Es una representación jerárquica donde el eje X muestra la población de muestras (cuanto más ancho es un bloque, más recursos consume) y el eje Y representa el stack trace o la jerarquía de llamadas. Si ves una «llama» muy ancha en tu gráfico, has encontrado tu cuello de botella.
Por qué el profiling siempre fue el «primo incómodo»
Si el profiling es tan útil, ¿por qué no lo hemos tenido integrado con el resto de nuestras herramientas hasta ahora? La respuesta se resume en una palabra: Fricción.
Hasta hace muy poco, el profiling era un ejercicio solitario y traumático. Primero, estaba el «impuesto del observador». Activar un profiler tradicional solía añadir un overhead de rendimiento de entre el 5% y el 20%. En un sistema que ya está al límite, añadir un 10% de carga para diagnosticar el problema es, a menudo, la receta perfecta para el desastre total.
Segundo, la fragmentación absoluta. Si trabajabas en Java, usabas VisualVM o YourKit. Si tenías microservicios en Go, usabas pprof. Si alguien lanzaba algo en Python, tenías que aprender a usar py-spy. En una organización moderna y políglota, esto significaba que cada equipo usaba herramientas diferentes, formatos de datos incompatibles y silos de información que no se comunicaban entre sí.
Peor aún era la falta de contexto. Podías ver un perfil de CPU que te decía que una función era lenta, pero no tenías forma de saber si esa lentitud afectaba a todos los usuarios o solo a los que usaban un método de pago específico. Tenías que intentar correlacionar manualmente los timestamps del perfil con las trazas de tu sistema de observabilidad, un ejercicio de adivinación que nadie quiere hacer bajo la presión de un incidente en producción.
La revolución tecnológica: eBPF y la donación de Elastic
Dos eventos han cambiado las reglas del juego y han permitido que OpenTelemetry Profiles sea una realidad viable hoy: la madurez de eBPF y un gesto de generosidad corporativa sin precedentes.
eBPF (extended Berkeley Packet Filter) es, posiblemente, la tecnología más disruptiva en la infraestructura de los últimos diez años. Es una máquina virtual dentro del kernel de Linux que permite ejecutar código de monitorización de forma segura y extremadamente eficiente. Gracias a eBPF, podemos hacer profiling de «todo el sistema» (desde el código de tu aplicación hasta las llamadas al sistema del kernel) con un impacto en el rendimiento casi imperceptible, a menudo inferior al 1%.
Lo más revolucionario de eBPF es que es no intrusivo. No necesitas modificar tu código, ni añadir librerías pesadas, ni siquiera reiniciar tus contenedores. El agente de profiling simplemente observa desde el nivel del kernel.
En 2024, la empresa Elastic decidió donar su agente de profiling continuo basado en eBPF a la Cloud Native Computing Foundation (CNCF) para integrarlo en OpenTelemetry. Esta donación no fue solo código; fue el «manual de instrucciones» y la base técnica que ha permitido a la comunidad de OpenTelemetry saltarse años de experimentación y pasar directamente a una fase de implementación madura.
OTel Profiles: Un estándar para gobernarlos a todos
La propuesta de OpenTelemetry Profiles no es inventar un nuevo tipo de profiling, sino estandarizarlo. Al igual que OTel hizo con las métricas y las trazas, Profiles define un formato común para capturar, transportar y almacenar estos datos.
El estándar se basa en pprof, el formato que Google diseñó y popularizó. Pero la verdadera magia reside en el OpenTelemetry Line Protocol (OTLP). Ahora, tu aplicación (o un agente externo eBPF) puede emitir perfiles que fluyen por el mismo «tubo» que tus trazas y métricas. Llegan al OpenTelemetry Collector, se procesan con los mismos metadatos y se envían a tu backend de preferencia (como Grafana Pyroscope, Parca o Dynatrace).
Esto elimina la fragmentación. Ya no importa si el código es Java, Rust o Node.js; los datos llegan con el mismo formato, la misma estructura y, lo más importante, el mismo contexto.
El «Santo Grial»: Los Span Links
La característica más potente de esta integración es la capacidad de conectar un Span (una unidad de trabajo en una traza) con un Profile. Mediante el uso de context propagation, OpenTelemetry puede marcar los perfiles de ejecución con el trace_id y el span_id correspondientes.
Imagina la potencia de esto: estás revisando una traza distribuida y ves que una llamada a la base de datos fue rápida, pero el procesamiento posterior en tu servicio tardó 800 milisegundos. En lugar de preguntarte qué pasó, haces clic en un enlace dentro de la misma interfaz y se abre el flame graph exacto de esos 800 milisegundos. No es un perfil promedio de la última hora; es la radiografía exacta de esa petición lenta.
Más allá de la CPU: Un abanico de posibilidades
Aunque solemos obsesionarnos con la CPU, OpenTelemetry Profiles abre la puerta a investigar otros recursos críticos que suelen ser «asesinos silenciosos» del rendimiento:
- Memory Profiling (Heap & Allocations): ¿Tu aplicación sufre de memory leaks? El profiling de memoria te muestra qué funciones están reservando más objetos y cuáles no los están liberando. Es vital para optimizar costes en la nube.
- Contención de Mutex (Lock Profiling): A veces tu CPU está baja, pero tu aplicación es lenta. ¿Por qué? Porque tus hilos están peleándose por un recurso bloqueado. El profiling de bloqueos revela dónde está el cuello de botella en la concurrencia.
- I/O Profiling: Muestra cuánto tiempo pasa tu código esperando a que el disco escriba datos o a que la red responda, permitiéndote optimizar las capas de persistencia.
Cuándo deberías empezar a usarlo
El profiling continuo no es solo para cuando el sitio se cae. Su valor real aparece en el día a día del ciclo de vida del software:
- En la optimización de costes (FinOps): Muchas empresas descubren, tras activar el profiling, que gastan el 30% de su factura de computación en una librería de logs mal configurada o en una serialización innecesaria. Identificar y eliminar ese «ruido» se traduce directamente en dinero ahorrado.
- En la prevención de regresiones: Al comparar los perfiles de la versión actual con los de la versión anterior en tu entorno de staging, puedes detectar si un cambio de código ha hecho que una función crítica sea un 10% más lenta antes de que llegue a producción.
- En la comprensión del sistema: Para un desarrollador nuevo, no hay mejor forma de entender cómo fluye el código que mirando un flame graph de una ejecución real.
El camino hacia la estabilidad
Es importante recordar que OpenTelemetry Profiles está actualmente en alpha pública. Esto significa que, aunque la base técnica es sólida y empresas como Grafana, Splunk o Dynatrace ya lo están apoyando, la especificación aún puede sufrir pequeños cambios.
Sin embargo, el mensaje para la industria es claro: el profiling ya no es opcional. El ecosistema se está alineando rápidamente. Los SDKs de lenguajes como Go y Java están a la vanguardia, mientras que para otros lenguajes, el agente eBPF ofrece una solución inmediata y poderosa.
Estamos entrando en una nueva era de la observabilidad. Una era donde ya no nos conformamos con saber que algo va mal, sino que pedimos saber exactamente por qué, en qué línea y bajo qué condiciones. OpenTelemetry Profiles es la pieza que faltaba en el rompecabezas para que el rendimiento deje de ser un arte oscuro y se convierta en una entidad exacta que ayude de verdad.
Para aprender más y pasar a la acción
Si quieres profundizar en los detalles técnicos o empezar a experimentar con estas herramientas, aquí tienes los recursos esenciales:
- OpenTelemetry Profiles Specification: La fuente de la verdad. Aquí encontrarás cómo se definen los metadatos y el modelo de datos del estándar.
- Google pprof documentation: Para entender el formato binario que sustenta casi todo el profiling moderno.
- Grafana Pyroscope: Uno de los backends de código abierto más populares y potentes para visualizar perfiles en formato OTel.
- Polar Signals Blog: Un recurso increíble para entender la magia de eBPF y cómo se aplica al profiling continuo.
- OpenTelemetry Collector Guide: El componente crítico para empezar a recolectar y enviar tus señales de profiling hacia tu stack de análisis.
