
¿Cuántas veces te has ido de una aplicación web porque tardaba más de un segundo en responder? Vivimos en una era en la que la impaciencia digital reina, y un simple retraso puede costarnos usuarios o clientes. Al mismo tiempo que la tecnología avanza rápido, la exigencia de los usuarios va incluso un paso por delante. Las organizaciones ya no pueden permitirse tener aplicaciones “funcionando” en el sentido más básico de la palabra; hoy, además de estar disponibles, deben ofrecer un rendimiento rápido, consistente y fiable. En este contexto, aparecen conceptos como los Objetivos de Nivel de Servicio (SLOs) y los Indicadores de Nivel de Servicio (SLIs), cuya finalidad es medir y garantizar la calidad de un servicio de forma que responda a las verdaderas necesidades del usuario.
Sin embargo, en medio de esta vorágine de cifras y porcentajes de cumplimiento, surge la pregunta: ¿estamos midiendo lo realmente importante? Numerosos equipos de desarrollo y de operaciones siguen centrando su atención en métricas clásicas (latencia promedio, disponibilidad del 99,9%, errores de servidor, etc.), cuando la experiencia del usuario podría estar sufriendo debido a factores que esos indicadores tradicionales no captan con suficiente nitidez.
A lo largo de este artículo, realizaremos un recorrido por la historia y la evolución de los SLOs y SLIs, analizaremos sus limitaciones y reflexionaremos sobre cómo adaptarlos a un enfoque más centrado en la experiencia real de los usuarios. Además, profundizaremos en cómo la plataforma Dynatrace puede convertirse en un aliado perfecto para medir, correlacionar e interpretar la salud de nuestro sistema desde un punto de vista funcional y de negocio. La idea es brindar una visión inicial y práctica de cómo reorientar la estrategia de fiabilidad de manera que refleje, ahora sí, el auténtico valor para el usuario.
1. De dónde venimos y hacia dónde vamos
1.1. El rol tradicional de los SLAs
Históricamente, el concepto de los Acuerdos de Nivel de Servicio (SLAs) surgió para formalizar un compromiso entre proveedores de servicios y clientes: “Si tu servicio deja de estar disponible o funciona por debajo de un estándar pactado, se aplican penalizaciones o compensaciones”. Estos acuerdos son la base contractual de la calidad, pero tienen una limitación importante: se centran casi siempre en la disponibilidad y el tiempo de inactividad, dejando de lado otros aspectos que inciden directamente en la percepción del usuario, como la velocidad de respuesta, la coherencia de datos o la experiencia en diferentes dispositivos.
1.2. El paso a SLOs y SLIs
Para refinar esta visión, se introdujeron los SLOs (Service Level Objectives) y los SLIs (Service Level Indicators). Mientras que un SLA es, en esencia, un contrato formal, un SLO es un objetivo interno que el equipo se propone cumplir, y un SLI es la métrica concreta que mide si ese objetivo se cumple. Por ejemplo, un SLO podría indicar “Mantener el tiempo de respuesta por debajo de 200 ms en el 99,9% de las peticiones”, y el SLI sería la métrica que registra el porcentaje de peticiones que cumplen con ese umbral de latencia.
Esta evolución permitió un mayor control e inmediatez en la respuesta a incidentes: en lugar de reaccionar cuando el cliente se quejaba o se incumplía el SLA, el equipo podía monitorizar si se estaba a punto de rebasar el SLO y tomar medidas preventivas. Sin embargo, sigue existiendo la duda de si estas mediciones captan de verdad la experiencia de las personas que utilizan la aplicación en el mundo real.
1.3. Retos en la era digital
Las aplicaciones modernas ya no son monolíticas que residan en un solo servidor. Con la proliferación de microservicios, contenedores y arquitecturas distribuidas, el panorama es mucho más complejo. Al mismo tiempo, la competencia por la atención del usuario es feroz: si tu aplicación no ofrece una experiencia fluida, el usuario se irá a la competencia en un par de clics. En este escenario, los objetivos y las métricas de nivel de servicio deben evolucionar para dar respuestas más orientadas a la experiencia final y no solo a la buena salud de la infraestructura subyacente.
2. Los límites de las métricas tradicionales
2.1. Disponibilidad vs. Experiencia real
La métrica de disponibilidad, expresada a menudo en términos de “nueves” (99,9%, 99,99%, etc.), suele ser la protagonista. Sin embargo, hay escenarios en los que un servicio técnicamente está “arriba” pero no brinda una buena experiencia de usuario. Pensemos en tiempos de respuesta excesivos, errores intermitentes o funcionalidades degradadas: la plataforma está operativa, sí, pero el usuario sufre retrasos o limitaciones que no se reflejan en un simple “OK” vs. “Down”.
2.2. Latencia media vs. Percentiles
Hablar de latencia promedio o media (mean) puede resultar engañoso. Unos pocos valores muy altos pueden distorsionar la media, del mismo modo que un sistema con picos de latencia ocasionales, pero muy pronunciados, puede mostrar una media aceptable y, al mismo tiempo, frustrar enormemente a quienes les toque ese “pico”. Por ello, el uso de percentiles (p95, p99, p99.9) proporciona una foto más fidedigna del rendimiento. Estos percentiles muestran cómo se comporta el sistema en sus peores escenarios y cuántos usuarios se ven realmente afectados por una latencia inaceptable.
2.3. Métricas de infraestructura vs. Métricas de negocio
Otra crítica habitual es la obsesión con métricas como el uso de CPU, la ocupación de memoria, el throughput de la red o el número de errores de servidor. Estos datos sin duda son importantes para el diagnóstico técnico, pero no siempre reflejan la experiencia que recibe el usuario. ¿Cuál es el tiempo total que tarda un cliente en completar el proceso de checkout en un comercio electrónico? ¿Cuántos usuarios hacen clic en un botón, pero encuentran un error en el último paso? Este tipo de indicadores, a menudo llamados SLIs de negocio, son mucho más relevantes para entender la salud de la aplicación desde la perspectiva de la experiencia final.
3. SLOs y SLIs centrados en la experiencia del usuario
3.1. La relevancia del Real User Monitoring (RUM)
Para superar las limitaciones mencionadas, diversas empresas están adoptando la monitorización orientada al cliente final, conocida como RUM (Real User Monitoring). El RUM recopila datos de navegación, errores de JavaScript, tiempos de carga de página y otras métricas directamente desde el navegador o dispositivo del usuario, permitiendo una visión mucho más realista de cómo el servicio se está comportando “ahí fuera”.
Estos datos abren la puerta a definir SLIs más representativos:
- Tiempo de interacción: ¿Cuánto tarda el usuario en poder interactuar con la página de forma fluida?
- Errores en el frontend: ¿Qué porcentaje de usuarios sufre un fallo en algún script esencial?
- Rendimiento en distintos navegadores o dispositivos: ¿La experiencia móvil es satisfactoria o se ve muy penalizada?
Al final, si un usuario no puede terminar con éxito la acción que desea (comprar, registrarse, mandar un mensaje, etc.), de poco sirve que la infraestructura marque un 100% de disponibilidad.
3.2. Definición de SLIs de flujo de trabajo
En lugar de medir pequeñas porciones de la infraestructura, cada vez toma más relevancia el seguimiento de flujos de trabajo o transacciones completas. Por ejemplo, un SLI podría enfocarse en “porcentaje de checkouts completados en menos de 2 minutos” o “tiempo para cargar el informe financiero desde que se hace clic hasta que aparecen los datos”. Cuando definimos SLIs de esta manera, estamos cuantificando algo que la empresa considera crítico para la satisfacción del cliente.
Esta visión de conjunto ayuda a alinear las métricas técnicas con los objetivos de negocio, porque un SLO fallido en un flujo clave de la aplicación (por ejemplo, un bajo porcentaje de checkouts completados) afecta directamente a los ingresos o a la fidelidad de los usuarios.
4. Herramientas y metodologías para un mejor control
4.1. OpenTelemetry y la unificación de datos
La adopción creciente de OpenTelemetry como estándar abierto para la recopilación de trazas, métricas y logs brinda enormes oportunidades. Al estandarizar cómo se capturan los datos, se consigue tener un lenguaje común para instrumentar servicios en distintas tecnologías. Así, no es necesario reinventar la rueda o depender de un solo proveedor para obtener la visibilidad que necesitamos.
4.2. Shift Left en la observabilidad
La observabilidad ya no es un tema que se “descubre” en producción. Bajo el enfoque “Shift Left”, se busca integrar la instrumentación y la monitorización desde etapas tempranas del ciclo de vida del desarrollo (pruebas unitarias, entornos de preproducción, etc.), acercándose lo más posible a condiciones reales de tráfico, cargas y uso. Cuanto antes detectemos anomalías, menos costoso es corregirlas y menor el impacto sobre el usuario final.
4.3. IA y Aprendizaje Automático
La popularización de la IA y el Aprendizaje Automático (Machine Learning) en el ámbito de la observabilidad (AIOps) permite detectar patrones anómalos que podrían no ser evidentes a simple vista. Los sistemas dotados de IA pueden identificar relaciones entre picos de latencia y ciertos componentes, o predecir fallos futuros basándose en patrones históricos, todo ello en tiempo real. Así, los equipos de operaciones pueden ser proactivos y evitar que un pequeño contratiempo se convierta en un problema generalizado.
5. Introducción a Dynatrace
A la hora de implementar un enfoque de observabilidad integral, moderno y centrado en el usuario, uno de los referentes del mercado es Dynatrace. Esta plataforma se ha consolidado en los últimos años como una solución full-stack que recopila y correlaciona métricas, trazas y logs de manera automatizada, sirviéndose además de un potente motor de inteligencia artificial.
5.1. Enfoque “one agent”
Dynatrace adopta un modelo de agente único, capaz de instrumentar automáticamente aplicaciones, contenedores y hosts. Esta configuración simplifica notablemente el proceso de puesta en marcha, reduciendo la carga en los equipos de desarrollo y operaciones.
5.2. Motor de IA “Davis”
Uno de los grandes diferenciales de Dynatrace es “Davis”, su motor de inteligencia artificial, que no solo “recoge” los datos sino que los analiza en tiempo real, detectando incidencias o anomalías y proponiendo causas y posibles soluciones. Esto resulta muy útil en entornos con decenas o cientos de microservicios, donde rastrear manualmente cada dependencia puede ser una odisea.
5.3. Visión de negocio y UX
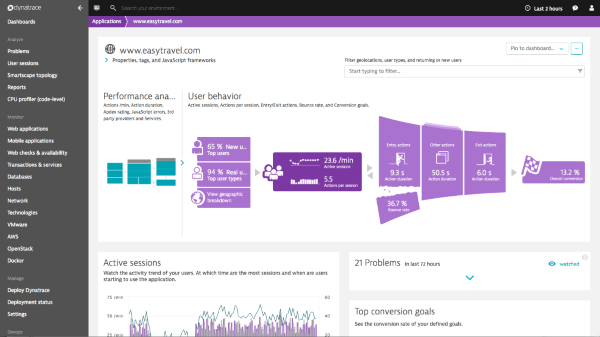
Dynatrace no se limita a mostrar métricas de CPU o tiempos de respuesta a nivel de servidor; integra también Real User Monitoring (RUM), permitiendo visualizar el rendimiento percibido por los usuarios finales y correlacionarlo con datos de negocio, como conversiones o transacciones completadas. Este enfoque facilita el camino hacia la definición de SLIs y SLOs orientados al usuario.
6. Cómo Dynatrace puede ayudarnos en la redefinición de SLOs y SLIs
6.1. Configuración de SLOs personalizados
Uno de los aspectos más potentes es la posibilidad de definir SLOs de forma flexible dentro de la propia herramienta. Dynatrace nos permite crear reglas que se ajusten a nuestras prioridades reales:
- Disponibilidad de un servicio clave en un rango de tiempo.
- Latencia en el p95 para un endpoint específico.
- Porcentaje de transacciones de checkout completadas con éxito en menos de 2 segundos.
Al estar integrado con el resto de la plataforma, cualquier brecha o riesgo en el cumplimiento de esos SLOs se puede detectar y alertar de manera automática.
6.2. Correlación de métricas de negocio
Dynatrace posibilita la correlación de datos técnicos (métricas de infraestructura, tiempos de ejecución de métodos, etc.) con métricas de negocio (tasas de conversión, tasas de error en el proceso de compra, etc.). De esta manera, si un pico de latencia en el servicio de pagos se corresponde con una caída en las ventas, el equipo puede priorizar de inmediato la solución de ese problema.
6.3. Real User Monitoring integrado
Gracias a su módulo de RUM, Dynatrace recoge información detallada sobre la experiencia del usuario, incluyendo aspectos como:
- El tiempo que pasa entre que el usuario hace clic y la aplicación responde.
- Errores de JavaScript o fallos en componentes del frontend.
- Ubicaciones o dispositivos con peor rendimiento.
Este nivel de detalle permite diseñar SLIs mucho más precisos, enfocándonos en flujos clave. Por ejemplo: “El 95% de los usuarios puede iniciar sesión en menos de 2 segundos”, o “El 99% de las visualizaciones de página cargan completamente en menos de 3 segundos”. Tener visibilidad en la experiencia real (no simulada) ayuda a la hora de alinear el objetivo del departamento de TI con las expectativas de los usuarios y, por ende, con los KPIs de negocio.
6.4. Alertas inteligentes y proactivas
Uno de los mayores dilemas en la monitorización es la saturación de alertas. Con Dynatrace, el motor de IA “Davis” reduce el “ruido” al correlacionar múltiples eventos que pueden tener una sola causa raíz. Así, en lugar de recibir 50 alertas que no sabes cómo priorizar, obtienes un evento consolidado que te señala el posible origen y te propone un orden de resolución.
7. Casos prácticos de aplicación
Para ilustrar la utilidad de Dynatrace en la definición de SLOs y SLIs, veamos algunos ejemplos concretos:
7.1. E-commerce con tiempos de respuesta críticos
Imaginemos un comercio electrónico que depende fuertemente de su página de checkout. El equipo decide definir un SLO que indica: “El 98% de las transacciones de checkout deben completarse en menos de 1 minuto, desde que el usuario hace clic en ‘Pagar’ hasta que aparece la confirmación”. Mediante Dynatrace, se instrumenta todo el proceso (frontend + backend + pasarelas de pago externas), se traza cada transacción y se puede observar, en tiempo real, si se están cumpliendo los objetivos. Si la latencia aumenta, la herramienta avisa con antelación, pudiendo el equipo corregir o escalar los recursos.
7.2. Aplicación SaaS B2B con SLAs estrictos
En entornos B2B (por ejemplo, soluciones de facturación o CRM en la nube), a menudo se pactan SLAs muy estrictos de disponibilidad y rendimiento. Con Dynatrace, se pueden definir SLOs como “Disponibilidad del 99,9% en horario laboral para la funcionalidad X” y “Tiempo de respuesta p95 < 300 ms para la API de informes”. Si en algún momento se aproxima un incumplimiento, la plataforma no solo emite alertas, sino que ayuda a profundizar en la causa (un componente saturado, una base de datos con queries lentas, un problema de red, etc.).
7.3. Servicios de streaming
Las plataformas de streaming (vídeo, música, etc.) están muy expuestas a la satisfacción inmediata del usuario. Un retardo de algunos segundos en la carga o buffering excesivo puede disparar la tasa de abandono. Definir SLIs basados en la experiencia de streaming (porcentaje de buffering aceptable, tiempo de inicio de reproducción, etc.) y correlacionarlos con la infraestructura subyacente permite tener una visión muy completa de la experiencia. Dynatrace, a través de RUM y la instrumentación del backend, ayuda a identificar dónde se localiza el cuello de botella (distribución de contenido, CDNs, servicios internos…) y a reaccionar con rapidez.
8. Retos y perspectivas de futuro
8.1. Aceptación cultural
La redefinición de SLOs y SLIs orientados a la experiencia del usuario no es solo un cambio técnico, también implica un cambio cultural. Muchos equipos de TI se han acostumbrado a medir la disponibilidad o la latencia media como si fuesen dogmas. Migrar a un enfoque que ponga al usuario final en el centro requiere formación, sensibilización y, sobre todo, la implicación de todas las áreas, desde marketing y producto hasta infraestructura.
8.2. Evolución constante de la infraestructura
Cada vez surgen más servicios en la nube, más entornos híbridos y más proveedores. Gestionar SLIs en un panorama tan distribuido requiere herramientas que sean capaces de agregar y correlacionar datos de muchas fuentes. Dynatrace y otras soluciones punteras están preparadas para ello, pero la complejidad no deja de crecer, y por ello la estrategia de observabilidad debe ser revisada y adaptada de forma periódica.
8.3. Automatización y DevOps
La filosofía DevOps ha traído consigo la integración continua (CI) y la entrega continua (CD), haciendo que el ritmo de releases sea mucho más rápido. En este contexto, la automatización de pruebas y el Shift Left en la observabilidad se convierten en un imperativo. La capacidad de inyectar datos de rendimiento, logs y análisis de fallos durante los pipelines de CI/CD es fundamental para detectar desvíos en los SLOs antes de que lleguen al usuario real.
9. Resumiendo
En los entornos actuales cada vez más competitivo y orientados a la experiencia digital, medir la fiabilidad de nuestras aplicaciones con SLOs y SLIs tradicionales (basados únicamente en disponibilidad y latencia promedio) puede resultar insuficiente. Necesitamos un enfoque centrado en el usuario, que refleje los procesos y flujos de trabajo clave para el negocio. Solo así sabremos de verdad si estamos ofreciendo un servicio valioso o si nos quedamos en métricas superficiales que no conectan con la realidad del usuario final.
El futuro de los SLOs y SLIs pasa por:
- Medir aquello que de verdad importa: los flujos de transacción, la experiencia real de navegación, la rapidez en tareas críticas, etc.
- Adoptar un enfoque multifuente: recoger datos de la infraestructura, pero también del cliente (RUM), de las pruebas de carga, de logs y trazas completas.
- Integrar la IA y la automatización: para detectar, correlacionar y anticipar problemas en entornos cada vez más complejos y distribuidos.
- Mantener un ciclo de retroalimentación: revisar los objetivos (SLOs) de manera continua en función de la evolución del negocio, la infraestructura y las necesidades de los usuarios.
En este contexto, la plataforma Dynatrace se erige como una aliada fundamental. Su modelo de agente único, su motor de IA (Davis) y la capacidad de vincular datos de negocio con métricas de rendimiento permiten a los equipos de observabilidad centrarse no solo en “qué tan rápido y cuántos errores hay”, sino en “qué tal están consiguiendo sus objetivos los usuarios”. Este cambio de perspectiva contribuye a que la organización se mueva hacia un escenario en el que la monitorización deja de ser un fin en sí mismo y pasa a ser una herramienta clave para garantizar que la experiencia del cliente sea la mejor posible.
Para técnicos de observabilidad, responsables de monitorización y equipos de desarrollo, la pregunta ya no es si debemos repensar nuestros SLOs y SLIs, sino cuándo y cómo hacerlo. Y la respuesta es: cuanto antes, mejor. El camino hacia una observabilidad inteligente y eficaz pasa por medir lo correcto: aquello que el usuario final realmente valora y que, al final del día, se traduce en la satisfacción y los ingresos de la empresa.
Últimas reflexiones
- Revisión periódica: es aconsejable analizar la validez de los SLOs al menos trimestralmente, ajustándolos a nuevas realidades de uso o nuevas funcionalidades en la aplicación.
- Colaboración multidisciplinar: involucrar a marketing, producto, negocio y equipos de desarrollo en la definición de los SLIs asegura que se midan los aspectos que de verdad importan.
- Formación y comunicación: introducir el concepto de SLOs y SLIs centrados en el usuario requiere un cambio de mentalidad; formar a los equipos y compartir las métricas con todos los implicados es esencial para que el cambio cultural se produzca con éxito.
En definitiva, la monitorización tradicional ha quedado atrás, y debemos avanzar hacia una visión más holística y orientada al uso real de nuestras aplicaciones. Herramientas como Dynatrace facilitan enormemente este salto, pero la decisión última de repensar qué medimos y por qué lo medimos es nuestra. “El futuro de los SLOs y SLIs: ¿Estamos midiendo lo correcto?” no solo es una pregunta retórica, sino un llamado a la acción para repensar la estrategia de fiabilidad y apostar por métricas con verdadero impacto en la experiencia del cliente. Y esa, al fin y al cabo, es la piedra angular de la transformación digital que las organizaciones de hoy necesitan para prosperar en el mañana.
