Llevo años trabajando con Dynatrace a diario y probando cosas open source por curiosidad en mi mini-servidor casero, un Lenovo ThinkCentre M710Q que tengo funcionando 24/7 en casa. Ya tenía Prometheus + Grafana montado en mi VPS, así que pensaba que sabía más o menos lo que me iba a encontrar al probar otra herramienta de monitoring open source.
Me equivocaba.
Un comando. Un minuto. 6.000 métricas.
La instalación de Netdata es, literalmente, esto:
curl -Ss https://get.netdata.cloud/kickstart.sh > /tmp/netdata-kickstart.sh
sh /tmp/netdata-kickstart.sh
Nada de definir exporters, nada de escribir un scrape_config, nada de decidir qué métricas quiero recoger. Un comando, systemd arranca el servicio, y accedes al dashboard en el puerto 19999:
http://<tu-ip>:19999
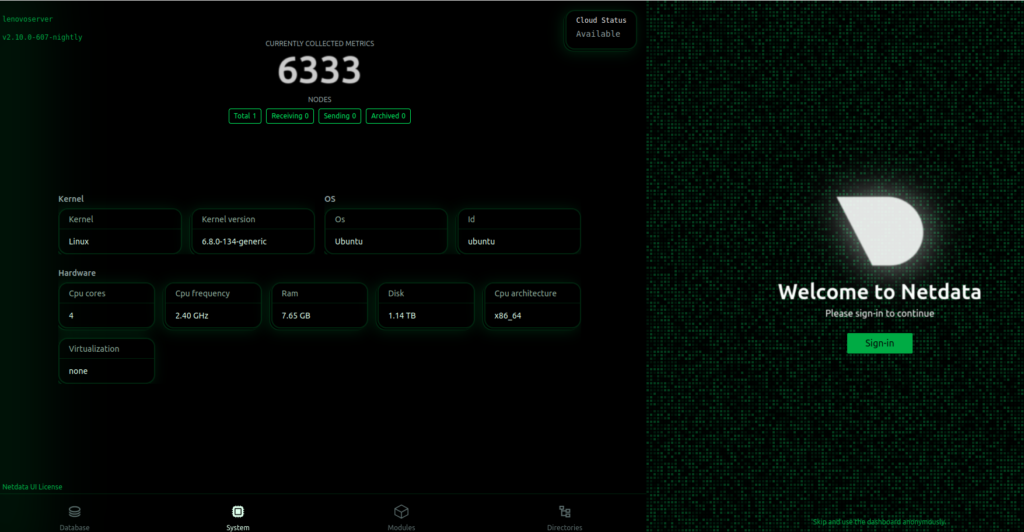
En el momento en que abrí el navegador ya tenía 6.219 métricas siendo recogidas de mi Lenovo. CPU, RAM, disco, red, procesos, servicios systemd, temperatura, particiones, interrupciones… Sin tocar un solo fichero de configuración.
Para quien viene de montar Prometheus + Grafana desde cero (definir el exporter correcto para cada cosa, escribir las queries PromQL, construir el dashboard panel a panel), esto es un cambio de filosofía completo. Prometheus te da control total pero tú construyes cada pieza. Netdata asume que quieres verlo todo ya, y decide por ti — y decide bien.
El dashboard en movimiento
Aquí es donde Netdata se gana el titular del artículo. No es solo que recoja muchas métricas: es que las ves moverse en tiempo real, cada segundo.
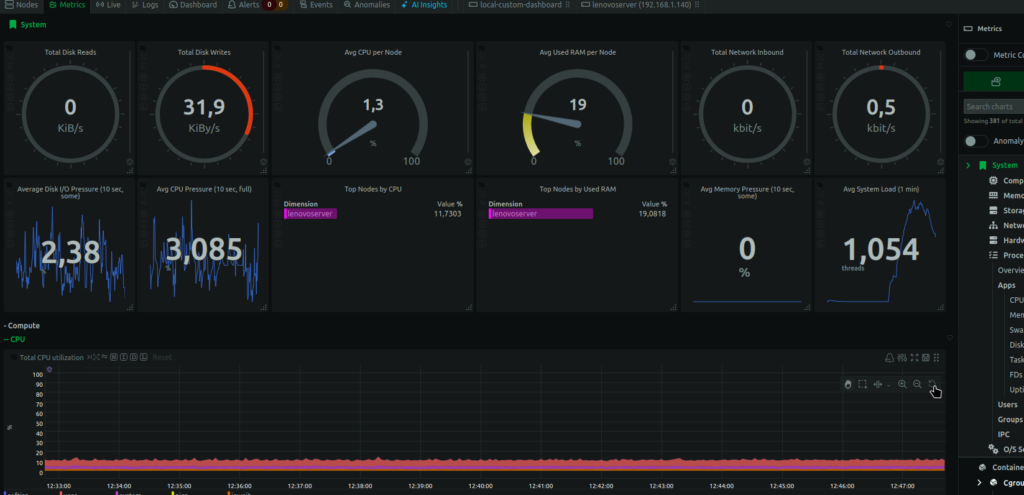
Los gauges circulares de «Avg CPU per Node» o «Avg Used RAM per Node» se actualizan solos delante de tus ojos. Las gráficas de líneas de abajo (CPU pressure, I/O pressure, system load) van dibujándose en directo, sin refrescar la página, sin esperar a que pase un intervalo de scrape de 15 o 30 segundos como en Prometheus.
Bajando en el menú lateral tienes secciones completas ya organizadas: Compute (CPU, Memory, Swap, Disk, Tasks…), Network, Hardware, Processes, O/S Services, Containers & VMs… Todo desplegable, todo ya con sus gráficas hechas.
La seguridad del homelab bien hecha
Un detalle que merece su propio párrafo: el dashboard corre sobre HTTP plano y sin autenticación por defecto. Eso, expuesto a internet, sería un problema serio. Pero en mi caso el Lenovo solo es accesible por su IP de Tailscale (una 100.x.x.x), no tiene ningún puerto abierto en el router. Es la forma correcta de montar esto para un homelab: cero superficie de exposición pública, acceso solo desde dispositivos que ya están en mi tailnet.
Alertas ya montadas, sin escribir una sola regla
Otra sorpresa agradable: Netdata trae alertas preconfiguradas de fábrica, sin que tengas que definir nada. En cuanto instalas, ya tiene reglas activas tipo «disco al 80%», «CPU sostenida alta», «RAM baja», «swap usándose demasiado», etc. Están en /etc/netdata/health.d/ (ficheros por categoría: disk.conf, cpu.conf, ram.conf…) y puedes editarlas o añadir las tuyas.
Para las notificaciones soporta email, Slack, Telegram, Discord, PagerDuty y varios más, configurables en /etc/netdata/health_alarm_notify.conf. Con Cloud, además, puedes centralizar y silenciar alertas desde un único sitio en vez de tener que tocar cada agente por separado.
¿Y la nube?
Netdata tiene una capa gratuita opcional llamada Netdata Cloud, que actúa como punto de acceso único si tienes varias máquinas: te logueas en app.netdata.cloud y ves todos tus nodos reclamados desde un solo sitio, con alertas centralizadas. Lo interesante es que tus datos no salen de cada máquina — Cloud solo hace de proxy cuando consultas algo, la base de datos de métricas sigue viviendo en local, en cada agente.
El plan gratuito Community tiene un límite: puedes conectar los nodos que quieras, pero solo 5 se pueden visualizar simultáneamente en el dashboard. Si tienes más máquinas (mi caso, con el Lenovo, un par de equipos Mint y la VPS), existe un plan Homelab, también gratuito, pensado exactamente para uso doméstico/personal no comercial, que quita ese límite y deja nodos y dashboards ilimitados.
Es completamente opcional: puedes usar Netdata en local para siempre y darle a «Skip and use the dashboard anonymously» cada vez, sin perder nada.
Lo que viene: varios equipos, un solo panel
Con un solo Lenovo ya impresiona. Pero tengo más máquinas en casa — otro par de equipos con Linux Mint — y Netdata permite centralizar todo eso de dos formas: reclamando cada nodo en Cloud, o montando una arquitectura Parent/Child, donde un nodo central (pienso usar la VPS) recibe el streaming de métricas de todos los demás y sirve un único dashboard, sin depender de ningún servicio externo.
Eso da para un segundo artículo entero.
¿Y el histórico? Cómo guarda los datos sin base de datos externa
Una duda que me surgió enseguida: si no hay que montar ni MySQL ni PostgreSQL ni InfluxDB, ¿dónde va todo esto?
Netdata trae su propio motor de almacenamiento interno, el dbengine, un formato de series temporales pensado para escribir rapidísimo y ocupar poco espacio. Vive en disco en /var/lib/netdata/dbengine/ y se gestiona completamente solo, sin que tengas que administrar nada.
Lo interesante es cómo organiza la retención, en tres niveles (tiers) que se van degradando con el tiempo para no comerte el disco:
| Tier | Resolución | Qué es | Retención por defecto |
|---|---|---|---|
| Tier 0 | cada 1 segundo | detalle máximo, recién recogido | 14 días |
| Tier 1 | cada 1 minuto | agregado (medias) | 3 meses |
| Tier 2 | cada 1 hora | agregado a largo plazo | 2 años |
Es decir: si algo raro pasó hace cinco minutos, lo ves segundo a segundo. Si quieres comparar la carga de hoy con la de hace cuatro meses, tiras de la media por hora — suficiente para ver tendencias, aunque pierdas el detalle fino.
Y ocupa realmente poco: en mi caso, con 6.400 métricas y casi 3 millones de samples guardados, el Tier 0 apenas llevaba 1 MB de un límite de 1 GB configurado. El límite por tier es ajustable en netdata.conf si algún día quieres ampliar la retención.
Esto también explica cómo funciona la pestaña de Anomalies: las puntuaciones de anomalía se calculan en tiempo real sobre los datos de Tier 0, así que para detectar algo raro reciente tienes toda la resolución que necesitas, sin depender de una base de datos externa que montar y mantener aparte — que es justo la pieza extra que sí tienes que gestionar con Prometheus.
Mi veredicto tras la primera hora
Si Prometheus + Grafana es como construir tu propio coche pieza a pieza — control total, pero trabajo real —, Netdata es subirte a uno que ya viene montado, con el motor rugiendo y el cuentakilómetros moviéndose desde el segundo uno. Para un nodo suelto o un homelab pequeño, no le he encontrado todavía ninguna pega. Para producción a gran escala, ya veremos — pero eso también es material para otro artículo.
Si tienes un Raspberry Pi, un NAS o cualquier trasto Linux cogiendo polvo, prueba el comando de arriba. Un minuto y lo vas a entender.
Material adicional
- Documentación oficial de Netdata — la referencia completa, bien organizada por temas
- Repositorio en GitHub — código fuente, issues, y para ver el ritmo real de desarrollo del proyecto
- Referencia de alertas y health checks — todas las reglas preconfiguradas y cómo escribir las tuyas
- Netdata Cloud — para quien quiera dar el salto a centralizar varios nodos
